
Machine learning-assisted pattern recognition and imaging of multiplexed cancer cells via a porphyrin-embedded dendrimer array†
Jiabao
Hu‡
,
Weiwei
Ni‡
,
Mengting
Han‡
,
Yunzhen
Zhan
,
Fei
Li
 ,
Hui
Huang
and
Jinsong
Han
*
,
Hui
Huang
and
Jinsong
Han
*
State Key Laboratory of Natural Medicines, National R&D Center for Chinese Herbal Medicine Processing, Department of Food Quality and Safety, College of Engineering, China Pharmaceutical University, 210009, China. E-mail: jinsong.han@cpu.edu.cn
First published on 6th November 2024
Abstract
Early cancer detection plays a vital role in improving the survival rate of cancer patients, underscoring the importance of developing cancer detection methods. However, it is a great challenge to achieve simple, rapid, and accurate methods for simultaneously discerning various cancers. Herein we developed a 5-element porphyrin-embedded dendrimer-based sensor array, targeting the parallel discrimination of multiple cancers. The porphyrin-embedded dendrimers were modified with various functional groups to generate differentiated interactions with diverse cancer cells, which has been validated by fluorescence responses and laser confocal microscopy imaging. The dual-channel, five-element array, featuring ten signal outputs, achieved 100% accuracy in distinguishing between one human normal cell and six human cancerous cells, as well as in differentiating among mixed cells. Moreover, the screen 6-channel array can accurately distinguish 9 cells from mice and humans in minutes through optimization by multiple machine learning algorithms, including two normal cells and 7 cancerous cells with only 1000 cells, highlighting the significant potential of a porphyrin-embedded dendrimer-based parallel discriminating platform in early cancer diagnosis.
1. Introduction
In the past decades, the incidence of cancer has steadily increased despite significant advances in cancer treatment and continuous decreases in the mortality rate, reaching an estimated nearly 20 million new cancer cases and 9.7 million cancer-related deaths globally in 2020 according to the American Cancer Society.1,2 Early cancer diagnosis can play a crucial role in decreasing the mortality rate and improving the life quality of cancer patients compared with the patients diagnosed later, underscoring the significance of developing accurate cancer detection.3,4 Currently, cancer detection mainly depends on imaging diagnosis, pathological diagnosis, biochemical analysis, and molecular biological analysis.5–7 These methods primarily rely on changes in biomarkers, typically including proteins, DNA, RNA, and metabolites, which originate from differences between normal cells and cancer cells.8–10 However, these biomarker-dependent approaches allow specific detection of only one cancer type, causing limited clinical applications in early cancer screening. Therefore, there is an urgent requirement to develop a simple and accurate method for the parallel identification of various cancer types.Array-based differential sensing technology that mimics the mammalian olfactory system, known as “chemical nose/tongue”, can distinguish multiple analytes through the pattern recognition principle, producing a unique fingerprint for each analyte.11–14 In recent years, array-based sensing methods have been widely applied in many related fields, including food safety and biology.15–34 Given the differences in the components and potential of cell membranes, intracellular proteins, and cellular environments among diverse cells,35–37 the array-based sensing platform can provide an expected way to distinguish cancer cells, contributing to the early cancer diagnosis.38–43 Dendrimers consisting of core and repeating units with a three-dimensional structure and various surface groups have been applied in various fields, ranging from materials and synthetic chemistry to biological and physical chemistry.44,45 Our group has exploited the fluorophore-labelled PAMAM-G5 dendrimer for the parallel discrimination of bacteria and beta-amyloids.46,47 While commercially available PAMAM exhibits good water solubility, it lacks inherent fluorescence and can only be modified at the terminal groups, resulting in limited applications. Porphyrins are naturally occurring macrocyclic compounds characterized by strong light absorption, high emission, and rich coordination chemistry and extensively utilized in biomedical imaging and therapeutic studies.48–50 We wondered whether the combination of dendrimers and porphyrins can lead to the conspicuous parallel detection of various cells through available chemical modifications. Our aim is to gain higher generation dendrimers, such as dendrimers G3–G5, enhancing the variety of non-covalent interactions and improving responsiveness toward targeted analytes.
In this study, we developed a novel porphyrin-based G3 dendrimer parallel sensing platform to discern various cancer cells. This array consisting of a porphyrin-based G3 dendrimer modified with distinct peripheral hydrophobic groups exhibited pronounced differentiated interactions with various cells, including distinctly adhering to the cell surface and penetrating cytomembrane via translocation, resulting in different fluorescence activations from the disruption of the aggregation-caused quenching effect, which could be validated by the fluorescence responses and laser confocal microscopy imaging. This 5-element array can produce 10 output channels due to the dual-channel properties of sensing elements, and enable the rapid and sensitive identification of nine cell types using machine learning algorithms, including one human normal cell, six human cancerous cells, one mouse normal cell and one mouse cancerous cell. Moreover, the screen array through machine learning showed the overall detection accuracy improvement of various machine learning algorithms, revealing the importance and necessity of screening sensing channels. These results demonstrated the huge potential of a porphyrin-based G3 dendrimer array for early cancer detection.
2. Materials and methods
2.1 Materials
All solvents and reagents were purchased from commercial suppliers without further purification. The human lung adenocarcinoma epithelial cell line (A549), human prostate cancer cell line (DU145), human ductal carcinoma cell line (BT549), human malignant melanoma cell line (A375), human ovarian cancer cell line (SK-OV-3), human pancreatic cancer cell line (PANC-1), one non-cancerous human pancreatic cell line (HPDE6C7), mouse embryo cell line NIH/3T3 and mouse pancreatic cancer cell line PANC02 were obtained from the Cell Culture Center of the Institute of Basic Medical Sciences, Chinese Academy of Medical Sciences (Beijing, China). The fluorescence values were recorded on a Spectra MaxR ID3 Multi-Mode Microplate Reader (Molecular Devices, California, USA) at room temperature. The cytotoxicity test was carried out using Cell Count Kit-8 (CCK-8) on a multi-mode microplate reader.2.2 Cell culture
In this study, the DU145, BT549, HPDE6C7, PANC02, A549, and NIH/3T3 cells were cultured in RPMI-1640 medium, supplemented with 10% fetal bovine serum (FBS) and 1% penicillin–streptomycin, and incubated in an incubator maintained at 95% humidity and 5% CO2 at 37 °C. Similarly, the A375, SK-OV-3, and PANC-1 cells were cultured in a DMEM medium containing 10% FBS under identical conditions.2.3 Fluorescence titration experiment
Initially, each compound was diluted to 2 μM in phosphate-buffered saline (PBS). Next, 100 μL of each diluted solution was dispensed into a 96-well plate in ten replicates. Subsequently, 100 μL of A549 cell suspensions at varying concentrations (100![[thin space (1/6-em)]](https://www.rsc.org/images/entities/char_2009.gif) 000 cells per mL, 80000 cells per mL, 50000 cells per mL, 20000 cells per mL, 10000 cells per mL, and 5000 cells per mL) were added to the wells containing the sensor array. Fluorescence spectra were recorded using excitation wavelengths of 660 nm and 730 nm, with emission set at 425 nm. Formal testing identified the 10000 cells per mL concentration as optimal due to its significant response and effective discrimination among the samples. Thus, 100 μL of this concentration, approximately 1000 cells, was used to enhance the sensitivity and discrimination efficiency of the sensor array, ensuring precise differentiation between cell types.
000 cells per mL, 80000 cells per mL, 50000 cells per mL, 20000 cells per mL, 10000 cells per mL, and 5000 cells per mL) were added to the wells containing the sensor array. Fluorescence spectra were recorded using excitation wavelengths of 660 nm and 730 nm, with emission set at 425 nm. Formal testing identified the 10000 cells per mL concentration as optimal due to its significant response and effective discrimination among the samples. Thus, 100 μL of this concentration, approximately 1000 cells, was used to enhance the sensitivity and discrimination efficiency of the sensor array, ensuring precise differentiation between cell types.
2.4 Cell identification
The different cell types were diluted to a concentration of 10000 cells per mL using PBS. Subsequently, 100 μL of the suspension from each of the nine cell types was mixed with 100 μL of sensor solution and placed in a black 96-well plate (6 replicates) for cell detection. The fluorescence changes of the sensor were obtained at 660 nm and 730 nm at an excitation wavelength of 425 nm. The change in light intensity was expressed as (I − I0)/I0, where I and I0 represent the fluorescence intensity with or without the addition of the nine cell types.
2.5 Machine learning processing of data
All data were processed using Python 3.10.14, and the nine machine learning models and metrics (accuracy score) used were derived from scikit-learn (https://scikit-learn.org/stable/index.html). All data were first processed to obtain (I − I0)/I0 values for different channels, and then linear discriminant analysis (LDA) was performed using SYSTAT 13.0 software. In LDA, all variables were used in the model (full model), and the tolerance value was set at 0.001. The fluorescence response pattern was converted to a typical pattern. The Mahalanobis distance from each pattern to the centroid of each group in the multidimensional space was calculated, and the shortest Mahalanobis distance was used as an example for assignment. All data apply random forest (RF) and multi-layer perceptron (MLP) classifiers and systematically evaluated the impact of different feature sets on model performance. We first conducted recursive feature elimination (RFE) based on output features, followed by performance evaluation using the MLP. Next, principal component analysis (PCA) was applied for dimensionality reduction, selecting the principal components with a cumulative variance contribution rate greater than 95% to train various machine learning models. These selected principal components were then subjected to visual analysis.2.6 Cytotoxicity assay
The cytotoxic effects of compounds D1, D2, D3, D4, and D5 were assessed using the CCK-8. For cytotoxicity measurements, we selected a high concentration of 1 μM, commonly used in toxicity testing, and a lower concentration of 0.2 μM. A549 and NIH/3T3 cells were seeded into 96-well plates at a density of 8 × 103 cells per well in 100 μL of cell culture medium. After approximately 24 hours of incubation, the old medium was replaced with a fresh medium containing 10% CCK-8 solution and incubated for one hour. Each absorbance was measured at 450 nm using a microplate reader. Untreated cells served as controls, and each concentration of each compound was tested in triplicate.2.7 Confocal laser scanning microscopy (CLSM)
Compound D3 was selected for confocal microscopy analysis. BT49, PANC02, and PANC-1 cells were seeded at a density of 1.0 × 104 cells in confocal culture dishes and incubated for 24 hours. Subsequently, the cells were treated with 1 μM of D3 in a fresh cell medium for 30 minutes. After three PBS washes, images were captured using a FV3000 confocal microscope, with the excitation wavelength for D3 set to 420 nm and displayed in red. To ensure data comparability, all confocal microscope settings were maintained constant throughout the experiment. CLSM images were processed using ImageJ software.3. Results and discussion
To develop a live-cell fluorescent sensor array, a porphyrin was chosen as the signal reporting unit due to its conjugated aromatic structure, chemical and optical stability, large Stokes shifts, strong fluorescence emission, and ability to extend into the near-infrared region, making it ideal for live-cell imaging. Given that porphyrins are rigid, planar, and non-polar compounds, hydrophilic quaternary amine salts were introduced to enhance their water solubility, thus making them suitable for sensor construction. The resulting positively charged sensor engages in various non-bonded interactions with targets, and its large Stokes shift minimizes interference from cellular autofluorescence, thereby enhancing its applicability to biological samples. Our goal is to obtain higher generation dendrimers with more abundant non-covalent interactions and improved responsiveness toward targeted analytes, such as dendrimers G3–G5; however, the synthesis of dendrimers G4 and G5 was restrained by the solubility of the intermediates. Dendrimers 1–5 (D1–D5, Fig. 1A) were synthesized according to established methods, and the Adler–Longo method was used to prepare methoxy porphyrins.51 Subsequently, demethylation was performed using boron tribromide to generate porphyrins with exposed hydroxyl groups. After this step, dendrimeric porphyrins with branched chains were synthesized by amide condensation, and finally, the quaternary amination reaction was carried out. The synthetic routes of D1–D5 are shown in Scheme 1. Their excitation and emission spectra revealed a maximum excitation wavelength of 425 nm, while the porphyrin exhibited dual emissions at 660 nm and 730 nm (Fig. 2A and Fig. S1, ESI†), and its fluorescence lifetime and quantum yield are shown in Table S1 and Fig. S2 (ESI†). The dual-emission characteristic of the single molecule offers additional signalling pathways for the sensor. Upon interacting with cells, we anticipate that the dendrimer molecules will penetrate and aggregate within the cells, inducing optical changes that are detectable for analytical purposes (Fig. 1B).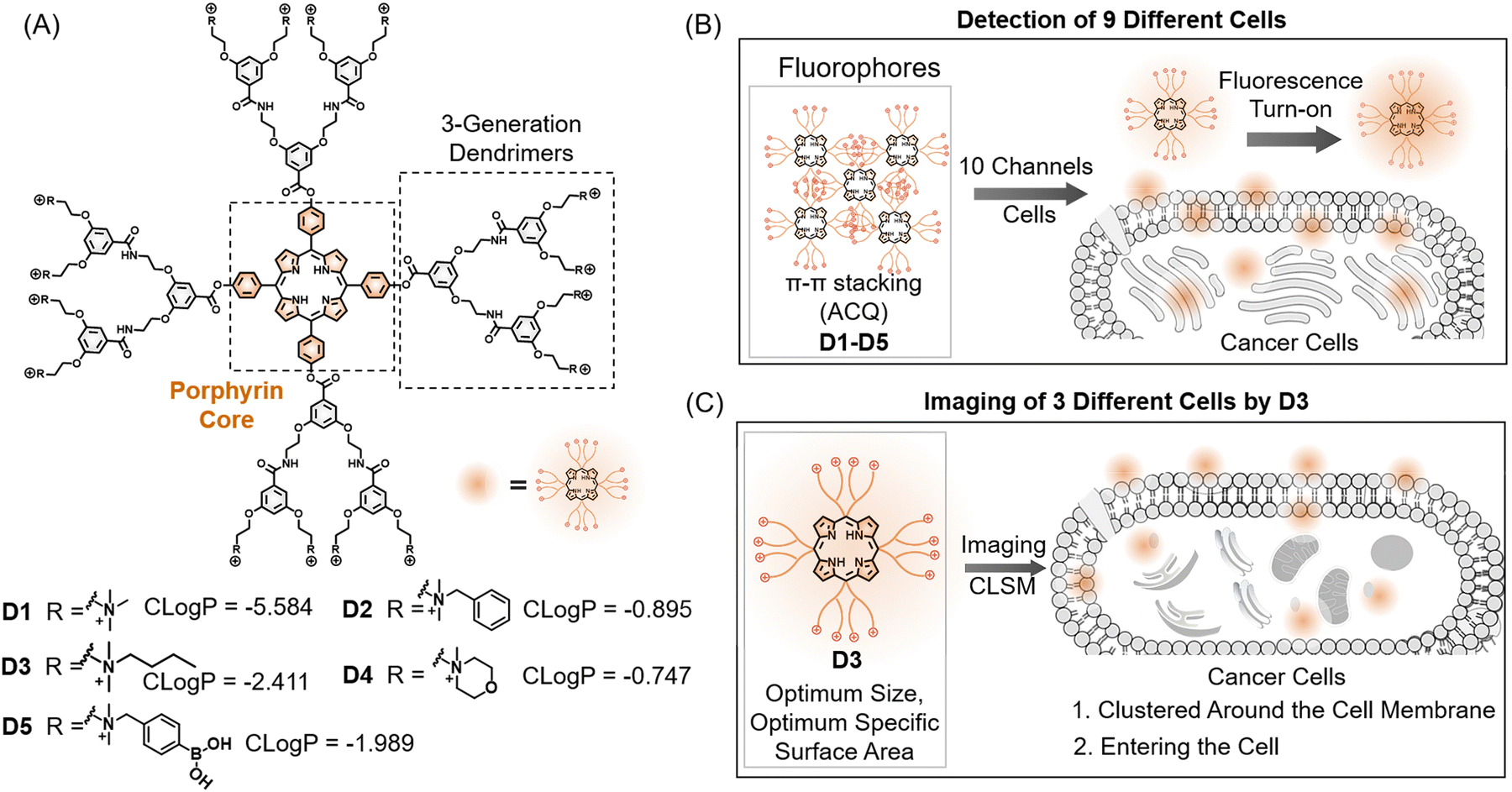 | ||
| Fig. 1 (A) The structures of D1–D5. (B) Hypothesized mechanism for cell recognition of D1–D5, enhancement of fluorescence intensity of D1–D5 after the addition of cells. (C) Schematic diagram of CLSM images of 3 different cells treated by D3. | ||
 | ||
| Scheme 1 Synthetic routes of D1–D5. | ||
 | ||
| Fig. 2 (A) Normalized excitation and emission spectra of D1. (B) Fluorescence changes of D1 and D3 upon incubation with different numbers of A549 cells. (C) LDA score plot for the first two factors of fluorescence patterns obtained for the sensor array with 4 cells. The scores were generated through LDA with 95% confidence ellipses. (D) LDA score plot of the first two factors of fluorescence responses to the 6 cancer cells and 1 normal cell from the sensor array. The scores were generated through LDA with 95% confidence ellipses. (E) Identification of 6 cancer cells and 1 normal cell. (F) ROC analysis of the two categories with an AUROC of 0.99. (G) LDA plot for the cell mixtures of HPDE6-C7 and PANC-1 with different ratios. The scores were generated through LDA with 95% confidence ellipses. (H) Confusion matrix plot of the output of the classifier from LDA for cell mixtures of HPDE6-C7 and PANC-1 with different ratio. | ||
To evaluate the feasibility of the dual-channel sensor array, we performed fluorescence emission titration experiments to investigate the fluorescence responses of the sensing element to cancer cells. In this experiment, we introduced varying quantities of A549 cells into the sensing system and monitored changes in fluorescence intensity. As illustrated in Fig. 2B, the fluorescence emission of the sensor element increased proportionally with cell concentration. Notably, at 500 cells per well, the spectral response of D3 remained relatively stable. However, at a density of 1000 cells per well, both D1 and D3 exhibited significant spectral alterations, attributed to the more frequent or intensified interaction between sensor elements and cells as the cell concentration increases. Considering the sensor's sensitivity, we established the condition of 1000 cells per well as the standard for further testing. These findings provide preliminary evidence support for applicability of dual-channel sensor arrays in bio-detection.
Then we further assessed the fluorescence responses of five sensors across different cell types. Our primary focus was on pancreatic cell lines, including the human normal pancreatic cell line HPDE6-C7, the human pancreatic cancer cell line PANC-1, and the murine pancreatic cancer cell line PANC02. To enhance the complexity of our detection targets, we also included the murine normal cell line NIH/3T3 in our test samples. We conducted linear discriminant analysis (LDA) using our 10-channel sensor array (Fig. 2C), achieving 100% accuracy across the four cell samples, revealing the sensor's potential in differentiating various cancer cell types (Table S2 and Fig. S3, ESI†).
Building on our previous research, we further investigated the sensor array's capability to differentiate between healthy and cancerous cells. Six human cancer cell lines and one normal cell line were selected for testing, with six replicates per set to ensure data reproducibility. Obviously, this array achieved 100% discrimination of the 7 types of cells, with clear clustered boundary in the LDA score map (Fig. 2D). By classifying 42 human cell samples, including both normal and cancer cells, we successfully distinguished them using LDA decision boundaries, highlighting the array's potential in cancer screening (Fig. 2E, Table S3 and Fig. S4, ESI†). We opted to employ LDA decision boundaries for subsequent receiver operator characteristic (ROC) curve analysis. The array accurately detected both healthy individuals and cancer patients, achieving an area under the receiver operating characteristic curve (AUROC) of 1 (Fig. 2F).
Considering the complex pathogenesis of pancreatic cancer and the challenges posed by subtle differences in structural features, gene expression, metabolic activities, and physiological functions of cells from the same organ, we conducted experiments with normal HPDE6-C7 cells and pancreatic cancer PANC-1 cells derived from the same organ pancreas. These experiments involved mixed samples at varying proportions (0:100%, 20:80%, 40:60%, 50:50%, 60:40%, 80:20%, and 100:0%). Our array displays distinctly different fluorescence responses for each mixture, enabling accurate classification on the LDA scoring map (Fig. 2G). Of the 16 blinded samples, two HPDE6-C7:PANC-1 = 60:40% were incorrectly identified as 40:60% and 20:80% (Fig. 2H, Table S4 and Fig. S5, ESI†). However, considering the practical application in large-scale early cancer diagnosis, this does not affect the judgment of whether cancer has occurred. These results highlighted the array's efficiency in detecting mixed cell populations, showcasing its practical potential in simulating complex clinical scenarios, such as analysing actual pancreatic cancer patient samples. These experiments not only validated the robust functionality of our array but also laid a strong foundation for its further development and deployment in clinical settings.
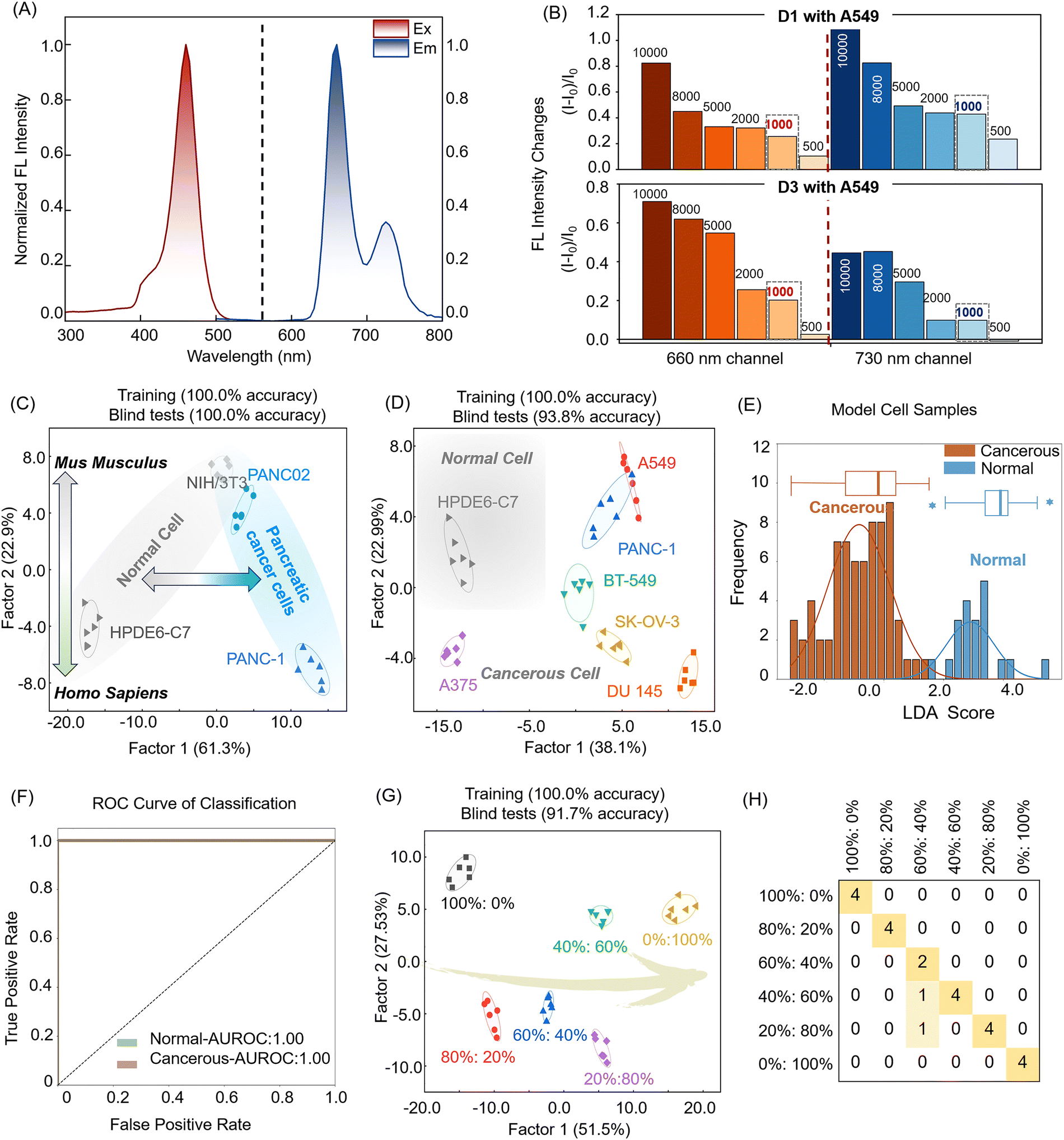
All the above experiments have demonstrated the effectiveness of our constructed array. To further expand its application range, we assessed the fluorescence responses of five elements to nine cell types, including six human cancer cell lines from different tissues, one normal human cell line, and two cancerous and normal mouse cells as controls, broadening the application scope of the sensor array (Table 1). We collected fluorescence emission data across ten channels at an excitation wavelength of 425 nm, performing six replicates per set to ensure data reproducibility. As shown in Fig. 3A, each channel in the array exhibited a distinct fluorescence response to the nine cell types. For example, with A549 cells, each channel displayed significant changes in fluorescence signals, characterized by substantial variation in intensity and pattern. Notably, channels 5 and 6 exhibited unusual increases or decreases in fluorescence when different cells were introduced, which may be due to the butane functional group on the surface of D3, possessing inherent hydrophobicity and thus binding to the cell membrane more rapidly with a shorter aggregation time on the cell membrane or intracellular space. Additionally, the heatmap in Fig. 3B illustrated the cross-reactivity of the 10-channel sensor array with various cells, revealing unique response patterns. Based on these findings, we concluded that this porphyrin-based sensor array can effectively generate a distinctive fingerprint for each cell type, confirming the viability of our strategy.
| Cell line | Organism | Tissue | Cancerous |
|---|---|---|---|
| A375 | Homo sapiens, human | Skin | Yes |
| A549 | Homo sapiens, human | Lung | Yes |
| BT549 | Homo sapiens, human | Breast | Yes |
| DU 145 | Homo sapiens, human | Prostate | Yes |
| SK-OV-3 | Homo sapiens, human | Ovary | Yes |
| PANC-1 | Homo sapiens, human | Pancreas | Yes |
| PANC02 | Mus musculus, mouse | Pancreas | Yes |
| HPDE6-C7 | Homo sapiens, human | Pancreas | No |
| NIH/3T3 | Mus musculus, mouse | Embryo | No |
 | ||
| Fig. 3 (A) Multichannel fluorescence response pattern of the sensor array to 9 cell types; error bars indicate the standard deviation of six replicate cells. (B) Heat map of cell fluorescence response (normalized relative fluorescence intensity change). 6 Replicates are shown for each cell line. (C) Canonical score plot for the first two factors of fluorescence patterns obtained for the sensor array with 9 cells. The scores were generated through LDA with 95% confidence ellipses. (D) Confusion matrix plot of the output of the classifier from LDA 9 cells. | ||
We applied Mahalanobis distance-based LDA to reduce the dimensionality of the output signals from the 10-channel sensor array, enabling the identification and analysis of patterns and trends among samples and constructing a model capable of identifying unknown samples. In this study, LDA transformed the training matrix (10 channels × 9 cell types × 6 replicates) into canonical scores to evaluate the discriminative power of the sensor array. As shown in Fig. 3C, the resulting score plots showed that factor 1 accounted for 38.6% of the total variance, while factor 2 accounted for 17.2%. Using these factors, the LDA map distinctly separated the nine cell types into distinct groups. Notably, human normal pancreatic cells were positioned in the upper left of the plot, clearly separated from the cancer cell populations, underscoring the model's efficacy in distinguishing between normal and cancer cells. Further cross-validation using jackknife-type classification matrices achieved 100% accuracy in distinguishing the nine cell types, confirming the array's high performance in cell recognition (Table S5 and Fig. S6, ESI†). To assess the model's predictive capacity for unknown samples, we conducted blind tests on 36 unclassified cell samples (9 cell lines × 4 replicates) using the established LDA training set. Only one of these samples was incorrectly identified (Fig. 3D and Table S6, ESI†), resulting in a high accuracy rate of 97.2%, reaffirming the sensor array's reliability and precision in practical cell-type detection applications. These results demonstrated the feasibility of a porphyrin-based array for rapid and efficient cell type identification through cross-responsive non-specific interactions, providing a valuable tool for the rapid classification and identification of cell types with significant potential in biomedical and diagnostic applications.
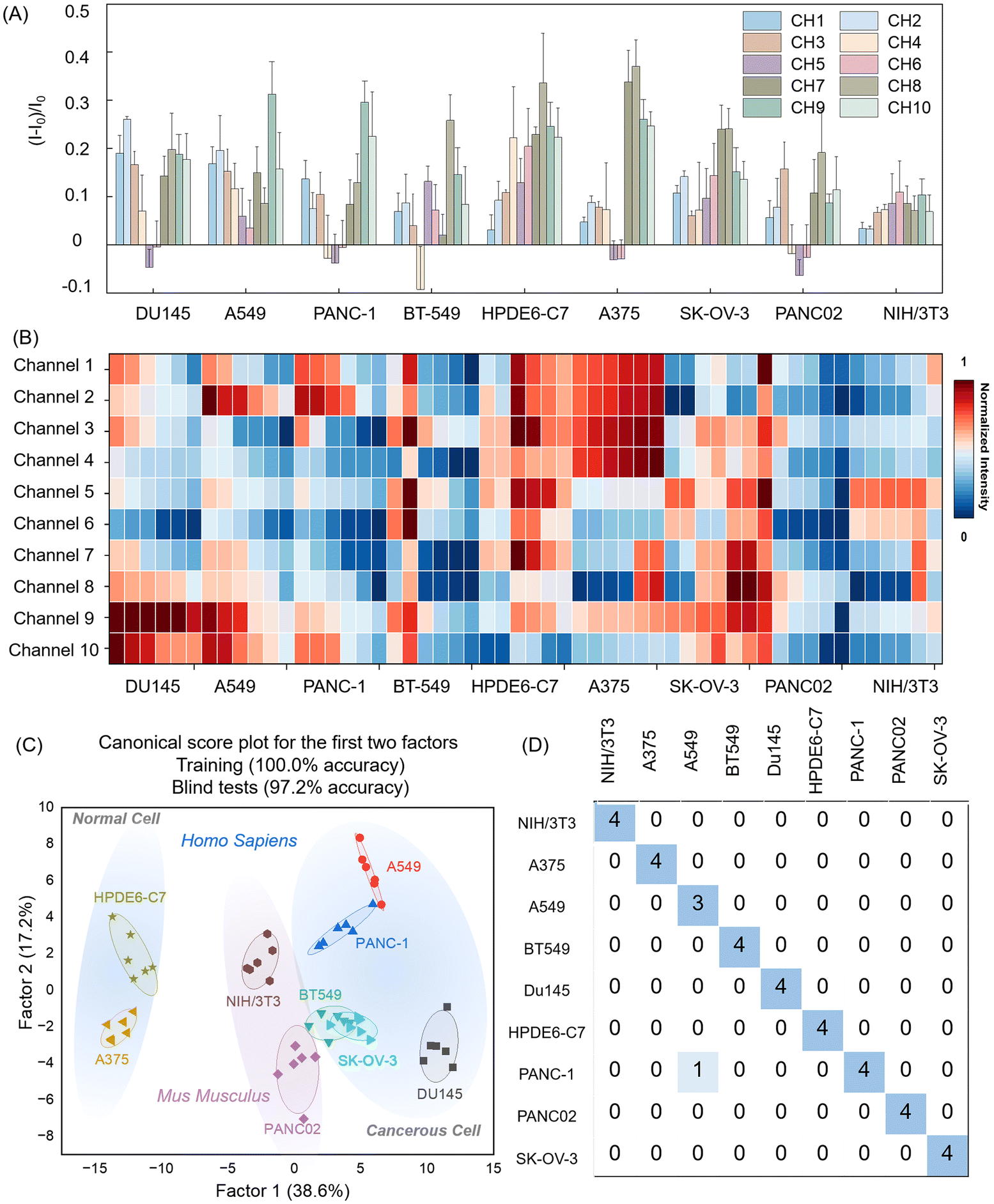
To establish detection and prediction models for various cell types and improve accuracy, we conducted in-depth data information acquisition. Initially, we examined various data split ratios between the training and test sets, incrementally adjusting from 9:1 to 5:5. Each adjustment was iterated 100 times to calculate the average accuracy, revealing that the optimal discrimination accuracy occurred at a 4:1 training-to-test set ratio (Fig. S7, ESI†). Based on these findings, we randomly selected eight samples for the training set and two for the test set from each data subset. Subsequently, we evaluated the performance of ten signal channel features using nine machine learning algorithms, including RF, logistic regression (LR), support vector machines (SVM), k-nearest neighbor (KNN), decision tree (DT), Gaussian naive Bayes (GNB), LDA, Bernoulli naive Bayes (BNB), and Gaussian process classifier (GPC), with each machine learning algorithm iterated 100 times (Table S7, ESI†). A comprehensive evaluation of the average accuracies demonstrated that six algorithms achieved test set accuracies exceeding 99%, with the LDA model showing the highest discriminatory power and nearly perfect training and prediction accuracy (Fig. 4A). These findings confirm not only LDA's efficacy in handling high-dimensional data sets but also its suitability for complex biological pattern recognition. This study underscores the significant potential of machine learning in cell type identification and cancer diagnosis, offering robust tools for future biomedical research.
 | ||
| Fig. 4 (A) Training and test set accuracy of the dataset on nine different machine learning algorithms. (B) Random forest model was used to rank the importance value of D1–D5 dual-channel 10 fluorescence signal features. (C) RF-RFE-MLP was used to screen 10 fluorescence signal features through 100 iterations, and the average accuracy of the MLP model was 95% when the remaining 7 fluorescence signal features were used. (D) After screening the model, it was observed that the accuracy of the model changed greatly from 7 fluorescence signal features to 6 fluorescence signal features, and the accuracy of the training set and test set was 7 fluorescence signal features on 9 machine learning algorithms. (E) Variance accumulation plot to observe the variance contribution value of each principal component. (F) The first six principal component heatmaps were selected with a threshold of 95% to observe the loading factors of the 10 fluorescence signals in each principal component. (G)–(J) Loading factors and corresponding contributions of each of the 10 channels in the two principal components of PC1 and PC2. (K) The proportion of variance explained by each principal component (PC) and the contribution of each principal component to the total variance of the data were observed in PC1 and PC2 principal component spaces. (L) Compared with the original 10 fluorescence channel signals, the accuracy of the selected 6 principal component features in the training set and test set on nine different machine learning algorithms is reduced, and the accuracy of various models is greatly improved. | ||
To save the operating time, reduce the complicated procedure and avoid useless sensing information, we employed the random forest-recursive feature elimination-multi-layer perceptron (RF-RFE-MLP) algorithm to screen the 10-channel signal array, aiming to achieve the minimal sensor combination that maximized discriminative performance. Using random forest-based feature importance evaluations and cross-validation across 100 randomly split datasets, with a MLP as the evaluation model, we recursively eliminated less critical channels (Fig. 4B). This process revealed a significant performance drop when reducing from seven to six channels, indicating that maintaining seven channels ensured 95% discrimination effectiveness (Fig. 4C). We further evaluated these seven channels using nine different machine-learning algorithms and repeating the process for 100 iterations. Although three algorithms achieved over 99% accuracy on the training set, their predictive performance was suboptimal. In contrast, the LDA model excelled on these seven channels, achieving a training accuracy of 98.2% and a prediction accuracy of 94.0% (Fig. 4D). This outcome underscored that optimizing sensor combinations and leveraging effective machine-learning algorithms can substantially reduce system complexity and cost while maintaining high recognition accuracy.
Furthermore, we also employed principal component analysis (PCA) for feature dimensionality reduction to address the unsatisfactory performance on the test set across all models, likely due to overfitting caused by an excess of features relative to categories. PCA was used to compress the 10-channel features into a linear combination, setting a threshold at 95% cumulative interpretable variance to retain information on most of the original data. The analysis in Fig. 4E indicated that the first six principal components explained 95% of the variance, suggesting that these components encapsulate nearly all essential information. Fig. 4F presents a heatmap of the combination of 10 channel signals in each principal component. Fig. 4GJ illustrate the coefficients and contributions of each channel within the corresponding principal components. Within a principal component, a specific channel may exhibit a significantly higher value, while others are markedly lower, highlighting the importance of this channel. Fig. 4K displays the proportions of variance explained by each principal component in the PC1 and PC2 spaces, along with the extent to which each principal component contributed to the overall data variation. We then retrained the nine algorithms using these six principal components to assess the impact of dimensionality reduction on model performance. The results demonstrated significant accuracy improvements compared with the original 10-channel features, with most achieving accuracy close to or at 100% (Fig. 4L and Table S8, ESI†). This enhancement in generalization and reduced overfitting risk highlighted the critical role of feature selection and dimensionality reduction in machine learning and data science. Such effective data preprocessing not only boosted model accuracy but also enhanced performance on unknown data, underscoring its practical significance for the development of sensor arrays in real-world application.
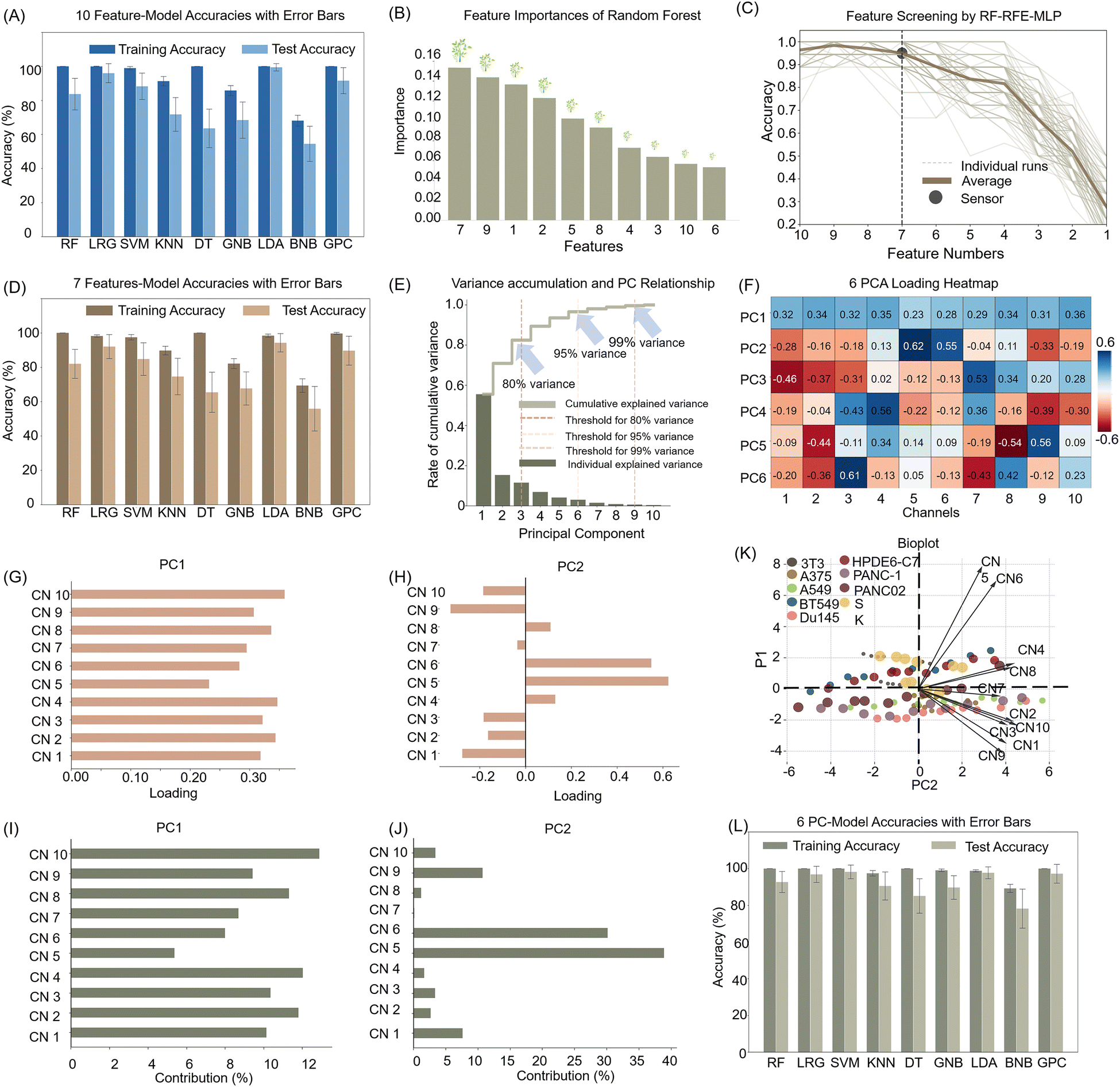
The success of the above experiments demonstrated the potential application of our constructed sensor array. To verify the interaction site and mode between the sensing elements and the cells, we conducted observations using laser confocal microscopy. To avoid cell death from excessive compound concentration, we initially assessed the cytotoxicity of the compounds before experiments to determine the appropriate concentrations and cell incubation conditions. Using the standard CCK-8 assay, we evaluated the cytotoxicity of D1–D5 on human non-small cell lung cancer A549 cells and mouse embryonic fibroblast NIH/3T3 cells. We maintained a cell concentration of 8000 cells per well and initially generated a dose–response curve correlating compound concentration with cell viability (Fig. S8, ESI†). Based on preliminary results, concentrations of 0.2 μM and 1 μM were selected for definitive testing. After 48 hours of incubation, cytotoxicity was evaluated using the CCK-8 assay. The results in Fig. 5A showed that cell viability remained above 95% at both tested concentrations, confirming that the compounds exert pimping toxic effects on cells at a concentration of 1 μM and are thus suitable for live cell detection and imaging applications.
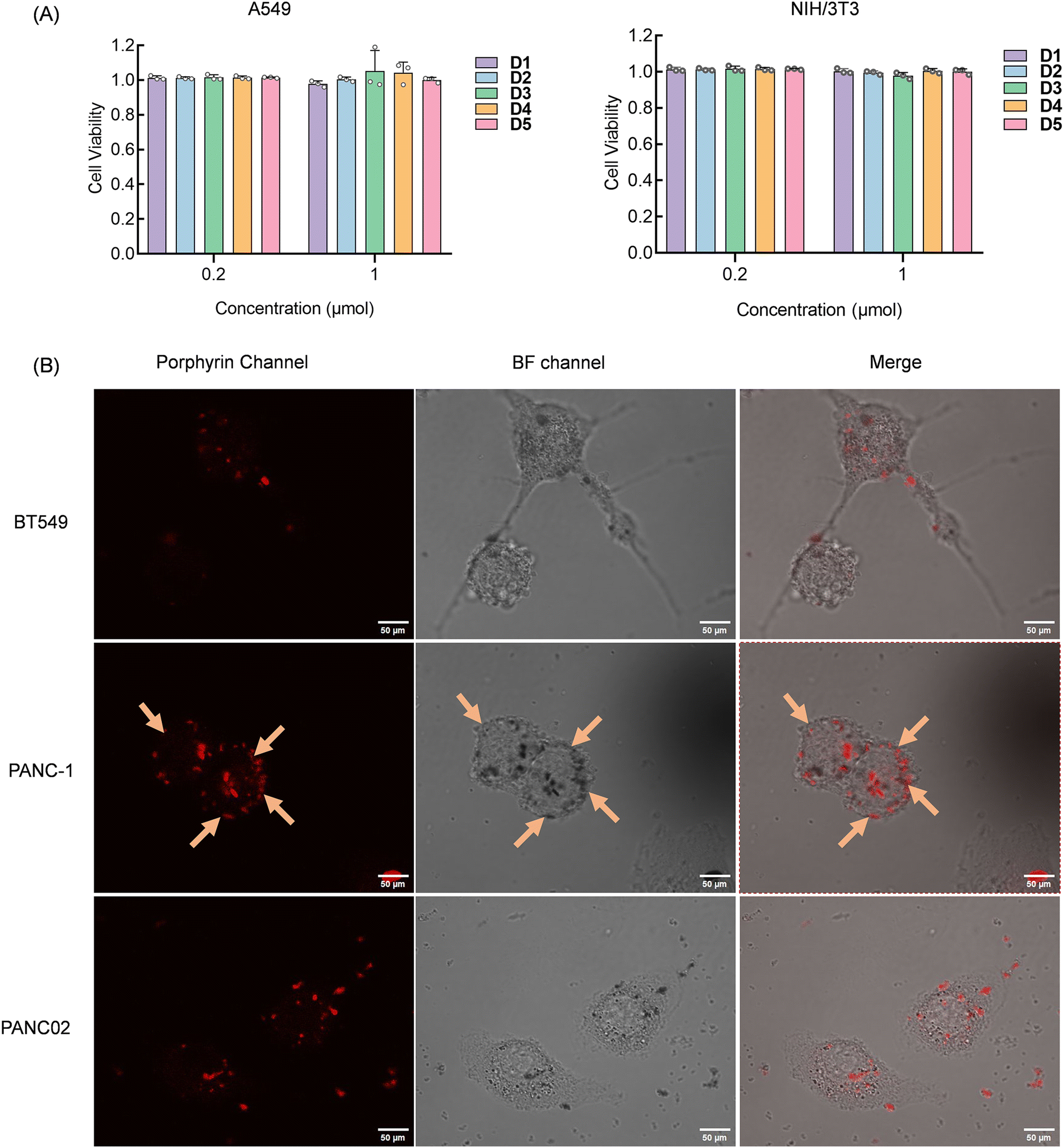 | ||
| Fig. 5 (A) CCK-8 experiment, cell viability of different concentrations of D1–D5 on A549 and NIH/3T3 cells, error bars indicate the standard deviation of three replicate cells. (B) CLSM images of the BT549, PANC-1, and PANC02 cells treated with D3. Each cell was incubated with a sensor for 30 minutes. The excitation wavelength was 420 nm. The collection wavelength was 620–700 nm. | ||
To further explore the parallel discrimination mechanism of our array, we selected two pancreatic cancer cell lines, PANC-1 and PANC02, due to quenching in channels 5 and 6, which D3 provided. Additionally, we chose the BT549 cell line, which uniquely showed fluorescence activation interaction with D3. Confocal imaging results depicted in Fig. 5B revealed that D3 initially bound to the cell membrane of PANC-1 and subsequently penetrated the cell interior. Imaging of PANC-1 and PANC02 exhibited D3 accumulation around the cell membrane, potentially accounting for the observed fluorescence quenching. Conversely, BT549 imaging displayed compound entry into cells, providing a distinct basis for cell discrimination. The variation in element interaction with different cell types leads to unique fluorescence changes for each element, thereby facilitating cell recognition.
4. Conclusions
In conclusion, we have developed a five-element porphyrin-embedded dendrimer-based sensor array, aiming at advancing cancer detection methodologies. The porphyrin-embedded dendrimer element integrally showed strong fluorescence signal enhancement across a range of cell types. This parallel sensing system with 10 sensing channels demonstrated rapid detection capabilities, identifying trace amounts of nine different cell types with only 1000 cells at low concentrations (1 μM) within minutes. The versatility of this sensor array is further enhanced by hybrid and binary classification detection methods. Notably, this non-specific array allows us to develop a rapid, simple, and universal diagnostic tool for identifying cell types and their states. The method requires a minimal number of cells and does not involve additional steps to extract cellular genetic materials, proteins, glycoproteins, or other biomarkers, nor does it depend on specific biomarkers or cell markers. After optimization with various learning algorithms, the screened six-channel array consistently maintained near-perfect accuracy across multiple computational cycles, underscoring the robust performance of the porphyrin-embedded dendrimer-based sensor array and machine learning algorithms, and the tremendous potential for large-scale early cancer screening applications.Author contributions
J. B. H., W. W. N., M. T. H. and Y. Z. Z. conducted most of the assays, and acquired and analyzed the data. J. S. H., and F. L. conceived the project, provided funding and supervision and designed the study. J. B. H., W. W. N., M. T. H., F. L., H. H. and Y. Z. Z. arranged the results and revised the manuscript. All authors have approved the final version of the manuscript.Data availability
The data supporting this article have been included as part of the ESI.†Conflicts of interest
The authors declare no conflicts of interest.Acknowledgements
This project was supported by the National Natural Science Foundation of China (82072017, 82472206 and 32272415), the Specialized Research Funds from the State Key Laboratory of Natural Medicines (SKLNMZZ2024JS43), and the Jiangsu Province Outstanding Youth Fund (BK20240093).Notes and references
- F. Bray, M. Laversanne, H. Sung, J. Ferlay, R. L. Siegel, I. Soerjomataram and A. Jemal, CA-Cancer J. Clin., 2024, 74, 229–263 CrossRef PubMed.
- D. Crosby, N. Lyons, E. Greenwood, S. Harrison, S. Hiom, J. Moffat, T. Quallo, E. Samuel and I. Walker, Lancet Oncol., 2020, 21, 1397–1399 CrossRef CAS PubMed.
- W. Hamilton, F. M. Walter, G. Rubin and R. D. Neal, Nat. Rev. Clin. Oncol., 2016, 13, 740–749 CrossRef.
- L. Yuan, Z.-Y. Xu, S.-M. Ruan, S. Mo, J.-J. Qin and X.-D. Cheng, Mol. Cancer, 2020, 19, 96 CrossRef.
- P. Zhang, Y. Tong, X. Huang, Y. Chen, Y. Li, D. Luan, J. Li, C. Wang, P. Li, L. Du and J. Wang, ACS Nano, 2023, 17, 16553–16564 CrossRef CAS PubMed.
- J. H. Park and J. H. Kim, Clini. Mol. Hepatol., 2019, 25, 12–20 CrossRef.
- J. Medlock, A. A. K. Das, L. A. Madden, D. J. Allsup and V. N. Paunov, Chem. Soc. Rev., 2017, 46, 5110–5127 RSC.
- W. H. Koppenol, P. L. Bounds and C. V. Dang, Nat. Rev. Cancer, 2011, 11, 325–337 CrossRef CAS.
- K. Pantel, R. H. Brakenhoff and B. Brandt, Nat. Rev. Cancer, 2008, 8, 329–340 CrossRef CAS.
- C. L. Sawyers, Nature, 2008, 452, 548–552 CrossRef CAS PubMed.
- Y. Geng, W. J. Peveler and V. M. Rotello, Angew. Chem., Int. Ed., 2019, 58, 5190–5200 CrossRef CAS PubMed.
- Z. Li, J. R. Askim and K. S. Suslick, Chem. Rev., 2019, 119, 231–292 CrossRef CAS PubMed.
- J. R. Askim, M. Mahmoudi and K. S. Suslick, Chem. Soc. Rev., 2013, 42, 8649–8682 RSC.
- T. Li, X. Zhu, X. Hai, S. Bi and X. Zhang, ACS Sens., 2023, 8, 994–1016 CrossRef CAS PubMed.
- J. Han, C. Ma, B. Wang, M. Bender, M. Bojanowski, M. Hergert, K. Seehafer, A. Herrmann and U. H. F. Bunz, Chem, 2017, 2, 817–824 CAS.
- J. Han, H. Cheng, B. Wang, M. S. Braun, X. Fan, M. Bender, W. Huang, C. Domhan, W. Mier, T. Lindner, K. Seehafer, M. Wink and U. H. F. Bunz, Angew. Chem., Int. Ed., 2017, 56, 15246–15251 CrossRef CAS PubMed.
- J. Han, M. Bender, K. Seehafer and U. H. Bunz, Angew. Chem., Int. Ed., 2016, 55, 7689–7692 CrossRef CAS.
- B. Wang, J. Han, M. Bender, S. Hahn, K. Seehafer and U. H. F. Bunz, ACS Sens., 2018, 3, 504–511 CrossRef CAS.
- J. Han, B. Wang, M. Bender, K. Seehafer and U. H. Bunz, Analyst, 2017, 142, 537–543 RSC.
- Y. Yu, W. Ni, Q. Hu, H. Li, Y. Zhang, X. Gao, L. Zhou, S. Zhang, S. Ma, Y. Zhang, H. Huang, F. Li and J. Han, Angew. Chem., Int. Ed., 2024, 63, e202318483 CrossRef CAS.
- H. Wang, M. Chen, Y. Sun, L. Xu, F. Li and J. Han, Anal. Chem., 2022, 94, 2757–2763 CrossRef CAS PubMed.
- H. Wang, L. Zhou, J. Qin, J. Chen, C. Stewart, Y. Sun, H. Huang, L. Xu, L. Li, J. Han and F. Li, Anal. Chem., 2022, 94, 10291–10298 CrossRef CAS.
- Y. Xu, C. Qian, Y. Yu, S. Yang, F. Shi, L. Xu, X. Gao, Y. Liu, H. Huang, C. Stewart, F. Li and J. Han, Anal. Chem., 2023, 95, 4605–4611 CrossRef CAS.
- W. Ni, Y. Yu, X. Gao, Y. Han, W. Zhang, Z. Zhang, W. Xiao, Q. Hu, Y. Zhang, H. Huang, F. Li, M. Chen and J. Han, Anal. Chem., 2023, 96, 301–308 CrossRef.
- J. Huang, H. Gu, G. Wang, R. Wu, M. Sun and Z. Chen, Anal. Chem., 2023, 95, 9107–9115 CrossRef CAS PubMed.
- X. Chen, C. Yao and Z. Li, TrAC, Trends Anal. Chem., 2023, 158, 116785 CrossRef CAS.
- Z. Li, Z. Wang, J. Khan, M. K. LaGasse and K. S. Suslick, ACS Sens., 2020, 5, 2783–2791 CrossRef CAS PubMed.
- Z. Li, L. Xu, H. Yuan and P. Zhang, Analyst, 2022, 147, 2930–2935 RSC.
- Z. Li and K. S. Suslick, Acc. Chem. Res., 2021, 54(4), 950–960 CrossRef CAS.
- M. Li, D. Wang, C. Peng and Z. Wang, Sens. Actuators, B, 2023, 378, 133183 CrossRef CAS.
- L. Li, C. Shen, X. Zhang and Z. Chen, Sens. Actuators, B, 2024, 403, 135205 CrossRef.
- S. Tai, J. Wang, F. Sun, Q. Pan, C. Peng and Z. Wang, Anal. Chim. Acta, 2023, 1283, 341929 CrossRef CAS PubMed.
- Y. Niu, J. Li, J. Gao, X. Ouyang, L. Cai and Q. Xu, Nano Res., 2021, 14(11), 3820–3839 CrossRef.
- Y. Yu, F. Shi, Y. Zhang, F. Li and J. Han, Future Foods, 2024, 4(1), 48–60 CrossRef.
- H. Döppler and P. Storz, Cell Metab., 2015, 22, 536–537 CrossRef PubMed.
- B. Kalyanaraman, Redox Biol., 2017, 12, 833–842 CrossRef CAS.
- V. Reshetnikov, S. Daum, C. Janko, W. Karawacka, R. Tietze, C. Alexiou, S. Paryzhak, T. Dumych, R. Bilyy, P. Tripal, B. Schmid, R. Palmisano and A. Mokhir, Angew. Chem., Int. Ed., 2018, 57, 11943–11946 CrossRef CAS.
- G. Zhang, Z. Wang, L. Ma, J. Li, J. Han, M. Zhu, Z. Zhang, S. Zhang, X. Zhang and Z. Wang, Adv. Healthcare Mater., 2024, 13, 2400241 CrossRef CAS.
- Y. Xiang, J. Liu, J. Chen, M. Xiao, H. Pei and L. Li, ACS Appl. Mater. Interfaces, 2024, 16, 15861–15869 CrossRef CAS.
- L. Wang, Y. Chen, Y. Ji, L. Wang, X. Liu, F. Wang and C. Li, Anal. Chem., 2024, 96, 11353–11365 CrossRef CAS.
- S. Rana, S. G. Elci, R. Mout, A. K. Singla, M. Yazdani, M. Bender, A. Bajaj, K. Saha, U. H. F. Bunz, F. R. Jirik and V. M. Rotello, J. Am. Chem. Soc., 2016, 138, 4522–4529 CrossRef CAS PubMed.
- Y. Ma, W. Ai, J. Huang, L. Ma, Y. Geng, X. Liu, X. Wang, Z. Yang and Z. Wang, Anal. Chem., 2020, 92, 14444–14451 CrossRef CAS.
- Z. Liu, G. V. Shurin, L. Bian, D. L. White, M. R. Shurin and A. Star, Anal. Chem., 2022, 94, 3565–3573 CrossRef CAS PubMed.
- M. E. Roth, O. Green, S. Gnaim and D. Shabat, Chem. Rev., 2015, 116, 1309–1352 CrossRef.
- J. Yang, Q. Zhang, H. Chang and Y. Cheng, Chem. Rev., 2015, 115, 5274–5300 CrossRef CAS.
- L. Xu, H. Wang, W. Xiao, W. Zhang, C. Stewart, H. Huang, F. Li and J. Han, Sens. Actuators, B, 2023, 382, 133519 CrossRef CAS.
- L. Xu, H. Wang, Y. Xu, W. Cui, W. Ni, M. Chen, H. Huang, C. Stewart, L. Li, F. Li and J. Han, ACS Sens., 2022, 7, 1315–1322 CrossRef CAS PubMed.
- T. Chatterjee, V. S. Shetti, R. Sharma and M. Ravikanth, Chem. Rev., 2016, 117, 3254–3328 CrossRef.
- R. Paolesse, S. Nardis, D. Monti, M. Stefanelli and C. Di Natale, Chem. Rev., 2017, 117, 2517–2583 CrossRef CAS.
- Y. Ding, W. H. Zhu and Y. Xie, Chem. Rev., 2017, 117, 2203–2256 CrossRef CAS PubMed.
- L. Wang, J. Liu, J. Wang, D. Zhang and J. Huang, J. Colloid Interface Sci., 2024, 653, 405–412 CrossRef CAS.
Footnotes |
| † Electronic supplementary information (ESI) available. See DOI: https://doi.org/10.1039/d4tb01861c |
| ‡ These authors contributed equally to this work. |
| This journal is © The Royal Society of Chemistry 2025 |