
Machine learning for recognizing minerals from multispectral data
Pavel
Jahoda†
 a,
Igor
Drozdovskiy
b,
Samuel J.
Payler
bc,
Leonardo
Turchi
b,
Loredana
Bessone
b and
Francesco
Sauro
*bd
a,
Igor
Drozdovskiy
b,
Samuel J.
Payler
bc,
Leonardo
Turchi
b,
Loredana
Bessone
b and
Francesco
Sauro
*bd
aCzech Technical University in Prague, Zikova 1903/4, 166 36 Praha 6, Czechia, Praha, Czechia. E-mail: pjahoda6@gmail.com
bDirectorate of Human and Robotics Exploration, European Space Agency (ESA/EAC), Cologne, 51147, Germany. E-mail: Francesco.sauro2@unibo.it
cAgenzia Spaziale Italiana, Rome, Italy
dDepartment of Biological, Geological and Environmental Sciences, University of Bologna, Italy, Bologna, Italy
First published on 22nd October 2020
Abstract
Machine Learning (ML) has found several applications in spectroscopy, including recognizing minerals and estimating elemental composition. ML algorithms have been widely used on datasets from individual spectroscopy methods such as vibrational Raman scattering, reflective Visible-Near Infrared (VNIR), and Laser-Induced Breakdown Spectroscopy (LIBS). We firstly reviewed and tested several ML approaches to mineral classification from the existing literature, and identified a novel approach for using Deep Learning algorithms for mineral classification from Raman spectra, that outperform previous state-of-the-art methods. We then developed and evaluated a novel method for automatic mineral identification from combining measurements with two complementary spectroscopic methods using Convolutional Neural Networks (CNN) for Raman and VNIR, and cosine similarity for LIBS. Specifically, we evaluated fusing Raman + VNIR, Raman + LIBS or VNIR + LIBS spectra in order to classify minerals. ML methods applied to combined spectral methods presented here are shown to outperform the use of a single data source by a significant margin. Our approach was tested on both open access experimental Raman (RRUFF) and VNIR (USGS, RELAB, ECOSTRESS) libraries, as well as on synthetic LIBS (NIST) spectral libraries. Our cross-validation tests show that multi-method spectroscopy paired with ML paves the way towards rapid and accurate characterization of rocks and minerals. Future solutions combining Deep Learning Algorithms, together with data fusion from multi-method spectroscopy, could drastically increase the accuracy of automatic mineral recognition compared to existing approaches.
1 Introduction
Fast and reliable identification of materials is important for many applications on Earth, including geological prospecting, material and engineering sciences and other analytical studies. For planetary surface exploration, particularly missions involving sample return, obtaining in situ information on the sample mineral composition is of critical importance due to time and weight constraints.1–3 Spectroscopy is an essential analytical technique for achieving this, allowing for the structural, chemical and functional properties of planetary materials to be accurately identified. Many robotics planetary exploration missions already take advantage of data provided by different spectroscopic methods. While early robotics landers were equipped with a single analytical instrument4 (e.g., Viking, Venera, Mars Pathfinder) several currently operating rovers, such as the Mars Curiosity rover, have multiple spectrometers.5 The upcoming ESA ExoMars 20226,7 and NASA Mars 20208 landers will also be equipped with analytical laboratories that are able to obtain multi-spectral data-sets from instruments such as Raman scattering (Raman), Visible-Infrared reflectance, Laser-Induced Breakdown (LIBS) and other types of spectrometers.Combining data from multiple spectroscopic methods can provide complementary chemical (e.g., LIBS or XRF) and mineralogical (e.g., Raman or VNIR) information that greatly assists in interpreting which materials are present in a sample. This has been demonstrated using combinations of LIBS together with hyperspectral images,9 XRF with VNIR,10 and Raman spectroscopy with Laser-induced fluorescence11 or with LIBS.12,13 However, classifying minerals based on combined multi-spectroscopic data is challenging, and requires significant time and expertise, both of which are often in short supply when operating in space or other remote locations. To address this problem, we have investigated a Machine Learning (ML) based approach for interpreting sample composition from multiple spectral datasets.
Various advanced ML algorithms have been shown to allow fast and accurate supervised classifications of different kinds of data (e.g., Schmidt et al.14). ML classification accuracy can be progressively improved by adding new training data to classification models without a reduction in recognition speed, making it an ideal technique for handling large datasets generated from multiple sources. Once trained, a variety of ML techniques can run on low power devices, making it suitable for deployable field devices.
Motivated by these benefits, in this study we investigate if a classification algorithm, or “classifier”, based on data from pairs of spectroscopic methods (Raman, VNIR, LIBS), can achieve more accurate mineral identification accuracy than a classifier applied to data from a single spectroscopic technique. Our novel approach to automatic mineral classification combines full-spectrum data from different pair-combined spectroscopic methods, and evaluates them against large datasets. Additionally, we assess different ML-classification algorithms, data fusion methods and ensemble techniques. We first evaluated several ML methods on their performance in identifying minerals using data from stand-alone (individual) analytical methods, including Raman, VNIR or LIBS, and then introduced our approach for combining the data from pairs of spectroscopic methods. In each section, we report the mineral classification accuracy‡ of these ML methods on spectra obtained from open access databases evaluated via cross-validation (“out-of-sample”) techniques.15–17 This work is part of the ESA-PANGAEA Mineralogical Toolkit, which aims to enhance the recognition of planetary minerals through mineral recognition software and database development. To ensure the software techniques described in this paper, and elsewhere, can utilize quality reference data for planetary exploration, we also compiled a custom multispectral data library for all known minerals present on the Moon, Mars and other planetary bodies.18 Developed and tested together, the software and database features of the Mineralogical Toolkit are conceived as a real-time decision support tool for future human and robotic planetary surface exploration missions.19,20 The Mineralogical Toolkit is integrated into ESA's Electronic Fieldbook, a field deployable system capable of supporting the future exploration of planetary surfaces.
2 Testing and improving stand-alone analytical methods
In order to develop methods for combining data from multiple analytical instruments, we first had to assess the state-of-the-art mineral classification methods built to work on datasets from single (individual) analytical techniques. This allowed us to first validate two novel ML techniques against the current best methods for Raman and VNIR spectra classifications, and then to choose the best options for the development of the pair combined analytical solutions. It is important to note that most of the comparison between the different ML techniques was performed on a Raman dataset as the VNIR and LIBS datasets available to us were limited. Therefore, we only report the classification accuracies of different ML techniques for Raman, as we did not feel it would be accurate to compare the ML methods applied to VNIR and LIBS classification given the limited datasets and classification studies in the literature. Nonetheless, we provide a short discussion on the potential applications for VNIR and LIBS.2.1 ML classification methods applied to Raman
ML methods have found many applications in Raman spectroscopy, including using several different classifiers to recognize minerals from their Raman spectra. This started by utilizing a mature and basic classification method using an algorithm called K-Nearest Neighbors (developed by Cover and Hart21), and used for mineral recognition, e.g., in Ishikawa and Gulick22 (referred to here as Method 1: KNN). Improvements followed, such as the use of Support-Vector Machine supervised learning models originally proposed by Cortes and Vapnik23 and applied to Raman spectra by Cui et al.24 (Method 2: SVM). Other examples include: Extremely Randomised Trees (Method 3: Trees), Weighted-Neighbors classifier (Method 4: WN), and Convolutional Neural Networks (Method 5: CNN).Extremely Randomized Trees is a subtype of Randomized Trees method originally proposed by Geurts et al.,25 and adopted for classification of Raman data by Sevetlidis and Pavlidis.26 Weighted Neighbors classifier is another improvement of the KNN method based on cosine similarity with special data preprocessing steps developed for Raman spectroscopy by Carey et al.27
Convolution Neural Networks, inspired by receptive fields in the animals visual cortex, were first introduced in the 1980s28,29 and became one of the most powerful pattern recognition methods including recently for Raman spectral classification by Liu et al.30
We assessed all five of these state-of-the-art methods for classifying minerals from Raman spectra, and added two new methods, which to our knowledge, have never been used to classifying mineral species before. These were: running averages of trained variables (Method 6: Averages), and an Ensemble of different network models (Method 7: Ensemble).
Method 6 aimed to improve the classification accuracy of the CNN method described by Liu et al.,30 by using running averages of the trained variables, instead of the values from the preceding training step. Specifically, we used an exponential decay, with a rate of 0.999.
Method 7 is an ensemble of 6 different neural network models (all of them use running averages) with different architectures. The data is processed by each neural network individually, and the softmax results (softmax scores) of all 6 are averaged to select the mineral corresponding to the highest score. Two of the architectures used are variations of the CNN described by Liu et al.30 Another two are variations of an architecture that focuses on rich feature representations of inputs through Parallel Feature Extraction Blocks31 (FeatEx). The final two architectures use variations of a standard convolutional network “VGG” net.32 Specifically, simpler versions of the VGG net consisting of six convolutional layers and 2–3 “fully connected layers” (where every node in the first layer is connected to every other node in the second layer), which allowed us to test the ensemble over multiple independent runs.
A strategy to improve classifier robustness, as well as to prevent overfitting of the ML model – and thus to improve the classification accuracy of the ML method – is to increase the size of the training (reference) dataset. To assist with this, data augmentation can be used to improve the training of neural networks by artificially enlarging a training dataset using label-preserving transformations, e.g., Liu et al.,30 Bjerrum et al.33 To investigate the effects of data augmentation on ML-classification performance on Raman spectra, we also evaluated different augmentation techniques.
2.1.1.1 Primary dataset for assessing different classification methods. In order to assess these classification approaches, each had to be tested on the same Raman spectra dataset. For this, the RRUFF Raman spectra database34 was selected due to its open access policy and widespread use across multiple studies. However, at the time of publication, the previous state-of-the-art classification methods used different releases of RRUFF, which is constantly evolving. Additionally, in these studies the authors used a variety of processes to split the data into training and testing sets, and diverse augmentation techniques to increase the size of the training set. Therefore, to accurately test and compare these classification methods under the identical conditions, we used a static version of RRUFF, kindly provided to us by C. J. Carey. This was the same dataset used in their work on ML-based mineral classification.27 The dataset consists of 3950 Raman spectra from 1214 different mineral species distributed as shown with green bars on Fig. 1. Our use of this database version and different preprocessing techniques (see below) appears to be the reason we report slightly different classification accuracies to the methods described in Liu et al.30 and in Sevetlidis and Pavlidis.26
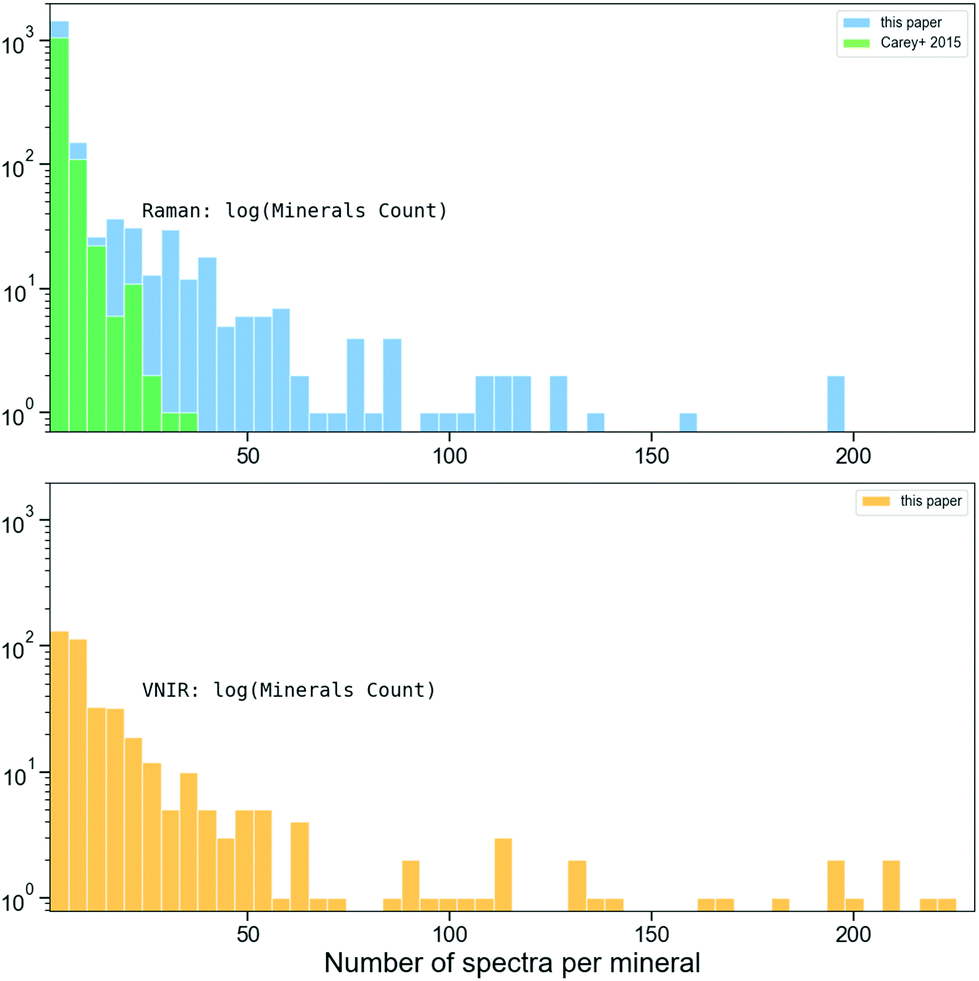 | ||
| Fig. 1 Histogram of the number of spectra per mineral class for the dataset used for single method classification tests. The top plots shows the class distribution for two Raman spectral libraries: in green is the primary dataset for assessing different classification methods (see section 2.1.1.1), while in blue is our updated data augmentation dataset (see section 2.1.1.1). The bottom plot (in yellow) is distribution of our VNIR spectral set (see section 2.2.1). For each histogram the bin width is 5, and the mineral counts axes are in logarithmic scale. Each of the available spectral sets is rather imbalanced, so the majority of minerals have low numbers of available spectrum examples. | ||
Typically, raw Raman spectra undergo a series of preprocessing before classifiers are applied.26,27,35 This is to eliminate noise (unwanted signals) and enhance mineral specific spectral features, including cosmic ray or bad pixel removal, spectra smoothing and baseline correction. The RRUFF dataset from C. J. Carey had already been baseline corrected. In addition to this, before feeding these data into any neural networks (described below), we performed linear interpolation on the data to convert each spectrum to a vector of 1715 intensity values, sampled uniformly from 85 to 1800 cm−1 following Carey et al.27 We also normalized the intensities of each spectrum to a range of 0 to 1, in order to address any disparities in intensity levels. In addition to the above, the KNN method also uses Principle Component Analysis (PCA) to reduce dimensionality before fitting the spectra, e.g., Ishikawa and Gulick,22 Cui et al.24
Following the principles of cross-validation outlined by Carey et al.,27 we split the dataset into a training set, constructed by selecting three spectra per mineral species at random, and assigned the remaining spectra to a testing set. For the training set, we removed outliers from all spectra for each mineral by finding an average spectrum for each class, and removing spectra that had a cosine distance from the average spectrum higher than 0.5. This outlier removal was performed to ensure the training set was not skewed by highly divergent spectra from random instrumental artifacts, or sample misclassifications.
2.1.1.2 Data augmentation dataset. While the classification approaches were tested on the static version of RRUFF, Data Augmentation was performed on the larger and more recent version of the RRUFF database (September 15th 2019). This choice is due to the necessity of having a larger and less homogenous dataset when testing Data Augmentation in order to increase the diversity of data available for training models. From the total of 27
![[thin space (1/6-em)]](https://www.rsc.org/images/entities/char_2009.gif) 078 spectra in the public archive of RRUFF, we selected only measurements labelled as of ‘excellent’ quality. These were already processed to be baseline corrected and have instrumental artefacts removed. The identity of each mineral was also confirmed via the XRD analysis. The resulting subset contains 8950 spectra representing 1705 mineral species, which the distribution histogram (shown as blue bars on top plot of Fig. 1) demonstrates as having a clear improvement in the coverage of mineral classes compared to previous studies.27 We then created a training set by selecting three spectra per mineral species at random. The remaining spectra, including lower quality spectra, were then used to create a testing set.
078 spectra in the public archive of RRUFF, we selected only measurements labelled as of ‘excellent’ quality. These were already processed to be baseline corrected and have instrumental artefacts removed. The identity of each mineral was also confirmed via the XRD analysis. The resulting subset contains 8950 spectra representing 1705 mineral species, which the distribution histogram (shown as blue bars on top plot of Fig. 1) demonstrates as having a clear improvement in the coverage of mineral classes compared to previous studies.27 We then created a training set by selecting three spectra per mineral species at random. The remaining spectra, including lower quality spectra, were then used to create a testing set.
We then examined several techniques to augment the training datasets. These techniques included testing the effects of shifting each spectrum left or right a few wavenumbers randomly, adding a single random value to each intensity value in a single spectrum, or adding random noise proportional to the magnitude of each wavenumber, all to increase the size of the dataset available. Furthermore, we evaluated the data augmentation techniques proposed by Bjerrum et al.,33 which had until now only been tested on NIR spectra. In addition to applying the Bjerrum et al.33 domain-specific transformations, we also tested the effects of domain-agnostic methods called “Synthetic Minority Oversampling Technique” (SMOTE).36 Every augmentation technique was used to double the size of the training samples available for each class without altering the distribution of the original dataset.
1. K-Nearest Neighbors algorithm (KNN),
2. Support-Vector Machine (SVM),
3. Extremely Randomised Trees (Trees),26
4. Weighted-neighbours classifier (WN) by Carey et al.,27
5. CNN method proposed by Liu et al.30
6. Running averages of trained variables (Averages),
7. Ensemble of different network models (Ensemble).
For clarity and reproducibility, at this stage no data augmentation was applied. In Table 1 we report mineral classification accuracies over 30 independent runs from these 7 methods. Accuracy is defined here as the percentage of mineral spectra that were classified as the correct mineral species.
| Method | Accuracy |
|---|---|
| Method 1 – KNN | 68.17% |
| Method 2 – SVM | 81.29% |
| Method 3 – trees | 80.92% |
| Method 4 – WN | 84.80% |
| Method 5 – CNN | 86.34% |
| Our method 6 – averages | 87.93% |
| Our method 7 – ensemble | 89.31% |
Compared to previous studies, the reported accuracy of Method 3 in Sevetlidis and Pavlidis26 was 88.8%, while Liu et al.30 reported an accuracy of Method 5 at 88.4%. As noted earlier, this discrepancy between our results is likely due our use of the different database versions and different preprocessing techniques. In any case, the comparison described here found that our new methods (Method 6 & 7), improved upon the previous state-of-the-art techniques for Raman spectra classification.
![[small mu, Greek, macron]](https://www.rsc.org/images/entities/i_char_e0cd.gif) ) of all four classifiers. The augmentations were again tested over 30 independent runs.
) of all four classifiers. The augmentations were again tested over 30 independent runs.
| Augmentation technique | CNN§ | KNN | SVM | Trees |
|
|---|---|---|---|---|---|
|
§With simple architecture. |
|||||
| No augmentation | 76.90 | 68.48 | 78.31 | 67.13 | 72.70 |
| Add random value | 76.17 | 69.03 | 78.64 | 64.19 | 72.00 |
| Shift spectrum | 74.77 | 69.01 | 76.93 | 68.89 | 72.4 |
| Noise | 76.95 | 69.30 | 78.30 | 68.47 | 73.25 |
| SMOTE | 76.54 | 68.44 | 77.84 | 67.69 | 72.62 |
| Offset, slope, multiply | 76.62 | 69.36 | 78.33 | 69.36 | 73.41 |
These data augmentation techniques do not appear to produce significant performance improvements on each of the tested classification methods for this particular dataset. We believe this can be explained by the small intra-class variance found in the original dataset.
2.2 ML classification methods applied to VNIR
Reflectance (aka ‘absorption’) spectroscopy in UV-Visual-IR wavelengths (VNIR) is another important technique that provides complementary information to Raman. This is because VNIR is active for anti-symmetric vibrations that alter the dipole moment, and Raman is active for symmetric vibrations that alter the polarizability, e.g., Larkin.37 As with Raman, VNIR is sensitive to chemical and physical properties, delivering a wide range of information about the analysed sample. However, in order to extract useful information, multivariate calibration of the spectral data is required.38 With the emergence of approaches based on using supervised neural networks trained on available spectroscopic databases, this task could be potentially simplified, allowing for mineral and geochemical classification to be directly inferred from unknown spectra.39–41To create training and testing sets, we combined spectra from the open access databases RELAB, issued on December 31st 2019,42 USGS version 743 and ECOSTRESS version 1.0.44,45 The final dataset comprised of 6231 spectra, representing 366 different mineral species. The combined dataset histogram distribution per mineral is shown on the bottom plot of Fig. 1. We again split the dataset into training and testing sets using the “leave-one-out” cross-validation.15
As mentioned above, we have not provided the comparison of various tested classification methods for the VNIR spectra here, as the dataset was limited and was not baseline corrected, making a comparison between methods inconsistent. However, we did find that Method 7, CNN Ensemble of six, provided the average accuracy of 69.71%.
2.3 ML classification methods applied to LIBS
LIBS provides information on the atomic chemical composition of a target material, rather than on its molecular structure, distinguishing it from VNIR and Raman spectroscopy. When combined with other analytical methods, this chemical composition is potentially valuable complementary information for identifying rocks and minerals. When LIBS is used as a stand-alone method, it can have severe limitations for properly identifying mineral species, since the same elemental composition can fit several mineral species with different crystalline structures, such as in polymorphs.The first algorithm, a cosine similarity algorithm, inspired by its common usage in text information retrieval, initially finds spectral peaks of the queried sample and records the theoretical spectral peaks of each atomic element. These peak intensities are then normalized and represented as weighted vectors.47,48 The algorithm then estimates chemical composition by computing cosine similarity between the queried weighted vector, and the weighted vector of the entire set of atomic emission line theoretical peaks across the NIST database. We then made mineral classification predictions by comparing the calculated elemental composition of a sample, to the elemental composition of minerals based on their empirical formulas (taken from webmineral.com or in some cases calculated using the Python software Molmass49).
The second algorithm uses a CNN trained on a synthetic dataset we created from a theoretical LIBS spectral library of random elemental compositions. While the cosine similarity has been used for qualitative analysis, CNN-based methodology has been recently proposed for LIBS quantitative analysis (e.g., Chen et al.,50 Li et al.51).
Both algorithms were compared by predicting the elemental composition of minerals containing elements occurring naturally on Earth (specifically, the first 81 elements of the periodic table). To achieve this, we used synthetic LIBS spectra of 1165 minerals. Using the LIBS NIST web interface, we opted the default combination of electron temperature, Te = 1 eV and electron density of ne = 1 × 1017 cm−3, and wavelength range between 185 nm and 950 nm. An example of calculated LIBS spectra for two end-members of olivine solid solution series shown on Fig. 2 demonstrates a clear distinction between those two endmembers. Nonetheless, the caution need to be taken when comparing the LIBS theoretical spectra as the LIBS NIST database could be incomplete lacking many important emission spectral lines of various elements (e.g., Ferus et al.52).
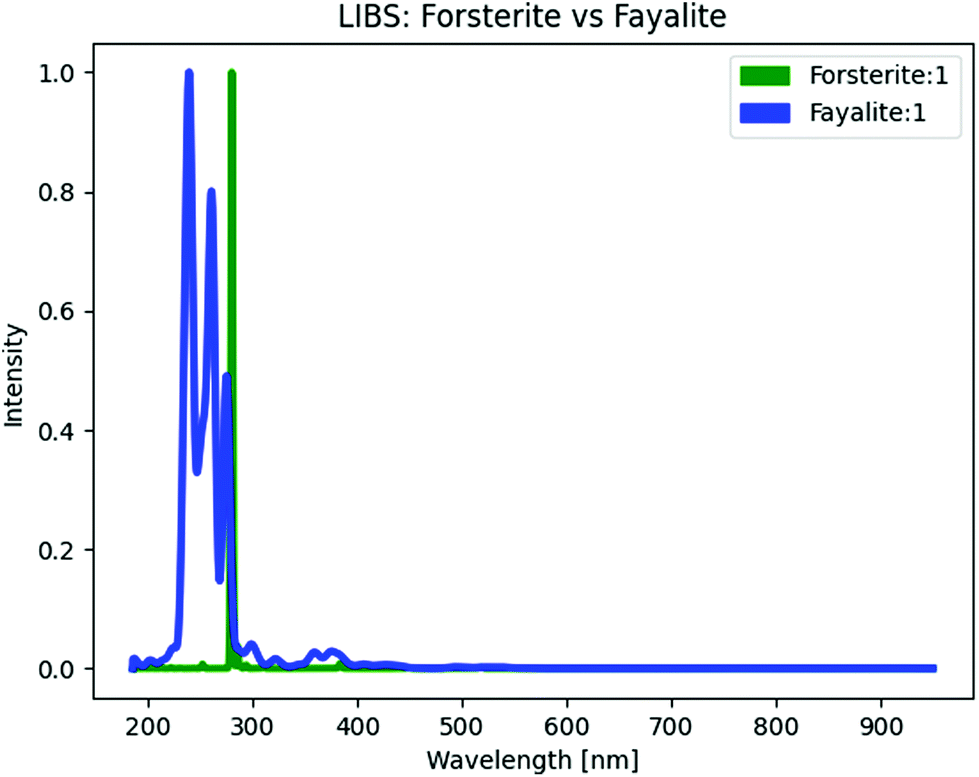 | ||
| Fig. 2 Synthetic LIBS spectra of Forsterite and Fayalite created from their calculated chemical abundances and online the NIST LIBS database.46 | ||
Although the validation tests of classifications based on computed LIBS spectra and calculated chemical compositions show apparent lower classification accuracy than using empirical spectral datasets for Raman and VNIR molecular vibrational spectroscopy, these results could be affected by the limitations of the synthetic LIBS spectra and by the differences in algorithms used to classify minerals from them. Nonetheless, considering the uncertainties mentioned above related to distinguishing minerals from atomic chemical composition alone, we might expect lower accuracy numbers for mineral classification with LIBS alone than using molecular vibrational spectroscopy, in particular for polymorphs which we labelled as different mineral classes within the dataset. Despite of this, we show in the following sections that combination of the LIBS based classification with Raman or VNIR are not beneficial in terms of recognition accuracy.
3 Pair-combined analytical methods
Following our assessment of the ML classification methods for individual spectroscopic methods, we then moved on to developing a system to analyse datasets from two spectroscopic methods. As mentioned, the main rationale was that using spectra related to molecular structures at different wavelengths (Raman/VNIR), paired with methods that probe molecular structure and atomic composition (Raman + LIBS and VNIR + LIBS), might yield a more accurate classification than either single method alone. We also tested the complementary use of Raman together with VNIR spectroscopy.3.1 Methodology
The success of the CNN's in classifying mineral spectra from stand-alone spectroscopic methods led us to pursue their use for classifying pair-combined datasets. However, we also had to develop a specific analysis pipeline combining several techniques to deal with data from two spectroscopic sources. Ultimately, the methods we used to combine VNIR and Raman data differed from the methods we used to combine Raman or VNIR together with LIBS. Each approach is detailed in sections 3.2 and 3.3.When combining Raman and VNIR, we either trained two separate classifiers to predict mineral species, and then combined these predictions, or we used a single two-stream convolutional neural network53 (see section 3.2 for more detail). This is in contrast to combining Raman and VNIR with LIBS. Here, we used the LIBS data to estimate elemental composition and subsequently fused this information with the VNIR/Raman prediction to classify mineral species. A flow diagram of our approaches to fusing Raman (or VNIR) and LIBS spectra for the recognition of minerals is presented on Fig. 3.
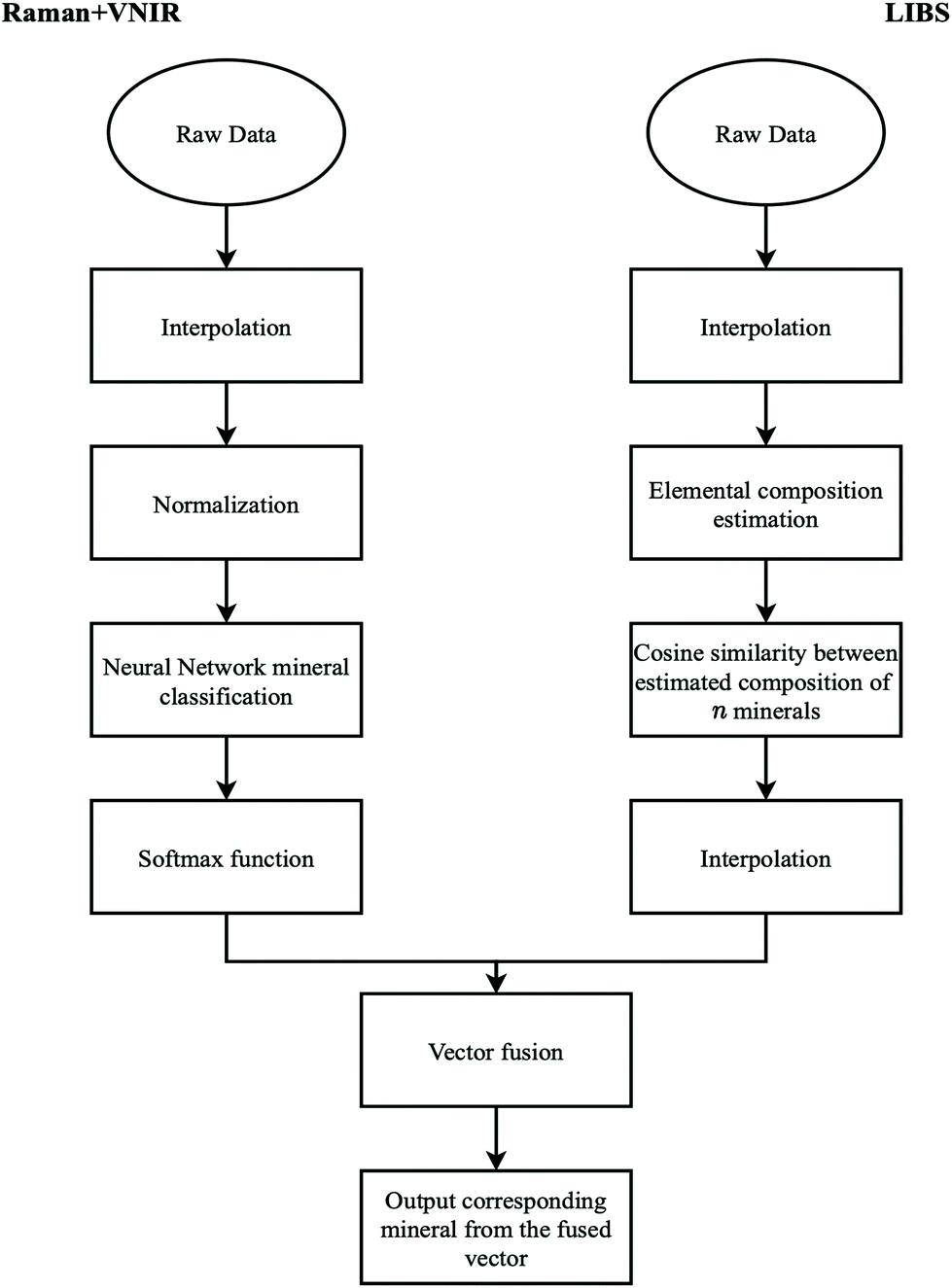 | ||
| Fig. 3 Simplified flow diagram showing our method for recognizing minerals from combined Raman/VNIR and LIBS spectra. | ||
In order to evaluate the robustness of combining any two spectroscopic methods, and to simulate more natural conditions, the work in the following sections did not exclude any lower quality spectra. To save computational time, whenever we used a CNN to test any combination of data obtained from different spectroscopic methods, we used a simple architecture with four convolutional layers and two fully connected layers, and used no data augmentation or exponential weighted averages of the trained variables. This Neural Network architecture has a decreasing convolutional kernel size, i.e., in the first convolutional layer the kernel size was 21, and in the last layer the kernel size was 3. We used the Rectified Linear activation function (‘ReLU’) and L2 kernel regularizer54 of 0.0001. We applied dropout regularization and 1D max pooling to prevent overfitting of the CNN.
3.2 Raman + VNIR
When identifying minerals from both Raman and VNIR spectra, we used a CNN as a classifier. We experimented with several ensemble techniques and took two different general approaches.The first approach consisted of training two different classifiers, one for Raman spectra and the other for VNIR spectra. We then combined the predictions (softmax scores) of each classifier by late fusion.53 We experimented with three late fusion methods: (i) averaging the predictions (Ave-p), (ii) multiplying the predictions (Mul-p), or (iii) having a support vector machine (SVM) to learn the relationship between the predictions (the softmax scores) of both classifiers and the ground truth labels. For the second approach, we used a single CNN with two separate recognition streams (Raman and VNIR), that fuses the streams at the last convolutional layer.55
Because the Raman and VNIR spectra were sourced from different archives created with different mineral samples, we were unable to pair-combine the Raman + VNIR spectral data of the same mineral sample. Instead, we created an artificial randomly pair-combined Raman + VNIR dataset for each mineral class. The spectra were compiled from the same open access databases described in the previous 2.1 and 2.2 sections: Raman spectra was obtained from RRUFF database and VNIR spectra from the RELAB, USGS and ECOSTRESS databases.18 However, this dataset was a subset of these larger databases, restricted only to minerals found in both Raman and VNIR databases. This totaled 5890 Raman and 7040 VNIR spectra from 259 different mineral species, which per mineral distribution is shown on Fig. 4. We used a ‘leave-one-out’ cross-validation method to split the dataset into training and testing sets by randomly selecting a single spectrum per mineral type for testing, and using the rest for training. We then paired each Raman and VNIR spectra from the same mineral species as synthetic data points (features). In Table 3 we report mineral classification accuracies of the compared methods averaged over 30 independent training runs.
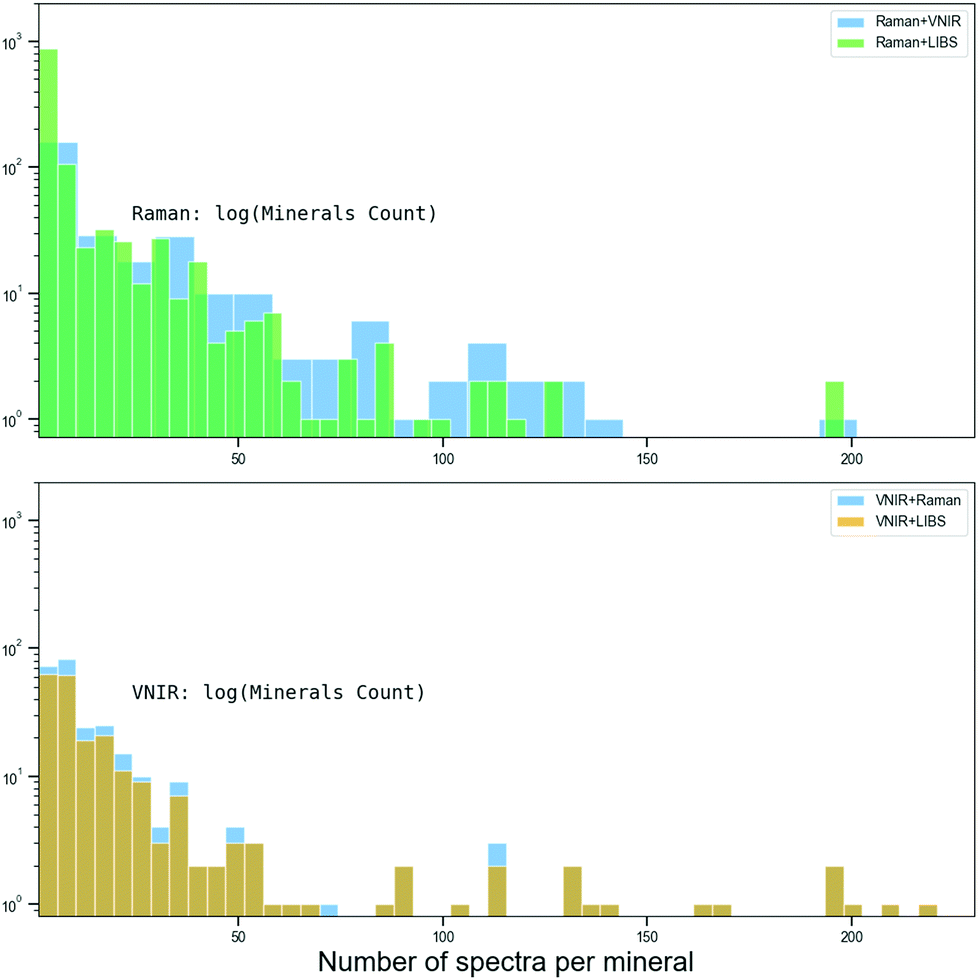 | ||
| Fig. 4 Histogram of the number of spectra per mineral class for the dataset used for pair-combined method of classifications. The top plot is the mineral class distribution for the Raman spectral sets, while bottom shows the distribution of VNIR spectral sets. | ||
| Method | Individual | Combined Raman + VNIR | ||||
|---|---|---|---|---|---|---|
| VNIR | Raman | Fusion | Ave-p | Mul-p | SVM | |
| CNN + CNN | 76.71% | 85.38% | 85.15% | 92.76% | 92.57% | 91.35% |
To be certain that combining different types of data would provide the best accuracy, we also created synthetic mineral samples by merging two different Raman spectra from the same mineral species. In this synthetic dataset, we achieved a mineral classification accuracy of 88.95%. This shows that our most accurate method (Ave-p) actually takes advantage of the information present in both Raman and VNIR datasets, instead of just using one type of data.
3.3 Raman + LIBS
To evaluate the combination of Raman and LIBS, we used a subset of Raman spectra from the RRUFF database sourced from minerals that have chemical compositions that could be calculated with the NIST LIBS Database. The resulting dataset had spectra from 1165 different mineral species. We then compared the mineral classification accuracy of two different combinations: (i) the Raman CNN classifiers with the LIBS CNN classifier, and (ii) the Raman CNN classifier with the LIBS cosine similarity algorithm. To combine the Raman classifier with the LIBS classifier, we again used late prediction fusion. The prediction of the CNN is outputted as a softmax score. In the case of the LIBS cosine similarity algorithm, the prediction output is a normalized vector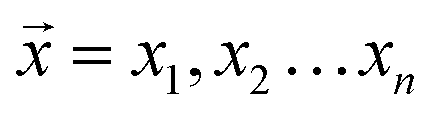 , where n is the n number of minerals and xi is the cosine similarity between the elemental composition of i-th mineral and the predicted elemental composition. We experimented with three different fusion methods: (i) averaging the predictions, (ii) multiplying the predictions, and (iii) squaring the predictions (Sq-p) of the LIBS classifier before multiplying it with the predictions of the Raman classifier.
, where n is the n number of minerals and xi is the cosine similarity between the elemental composition of i-th mineral and the predicted elemental composition. We experimented with three different fusion methods: (i) averaging the predictions, (ii) multiplying the predictions, and (iii) squaring the predictions (Sq-p) of the LIBS classifier before multiplying it with the predictions of the Raman classifier.
In Table 4 we report the mineral classification accuracies of the compared methods averaged over 30 independent training runs. The violin plot56 in Fig. 5 shows the full distribution of cosine similarities between the elemental composition of queried mineral spectra and the predicted elemental composition. From this figure, it is clear that the cosine similarity algorithm had a very low number of completely incorrect predictions, with low or no similarity between the elemental composition of queried mineral and the predicted elemental composition of the same mineral. This characteristic property allowed us to improve the mineral classification accuracy of the Raman + LIBS combined classifier, by initially squaring the prediction value of the cosine similarity algorithm before multiplying it with the Raman classifier prediction.
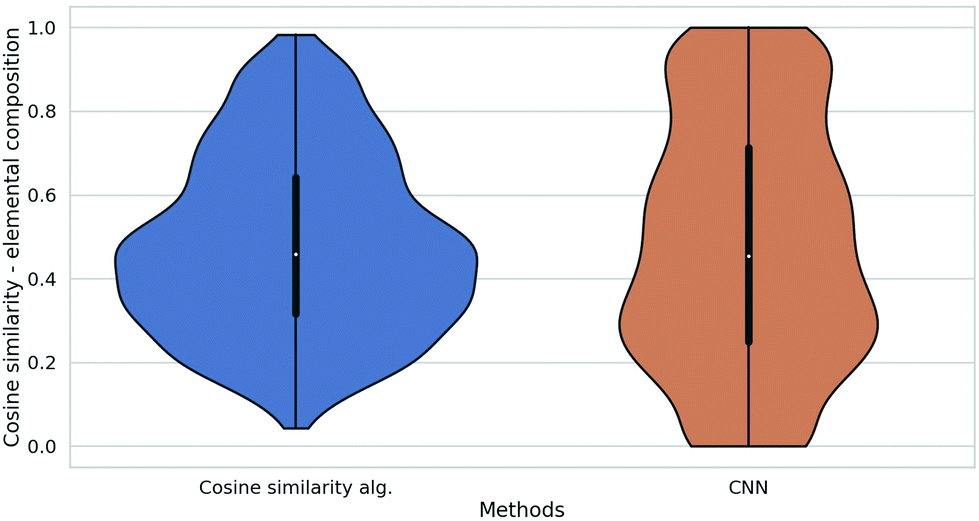 | ||
| Fig. 5 Violin plot: X-axis shows distributions of predictions by two different algorithms; Y-axis is the cosine similarity between the correct elemental composition and the predicted elemental composition. | ||
| Method | Individual | Combined Raman + LIBS | |||
|---|---|---|---|---|---|
| LIBS | Raman | Ave-p | Mul-p | Sq-p | |
| CNN + cosine | 6.44% | 79.04% | 80.40% | 81.92% | 83.21% |
| CNN + CNN | 8.98% | 78.88% | 78.04% | 77.69% | 76.82% |
3.4 VNIR + LIBS
To evaluate the combination of VNIR and LIBS spectra for mineral classification, we repeated the same procedures and methods used for the Raman and LIBS combination. To train the VNIR classifier, we again combined all the available spectra from the RELAB, USGS and ECOSTRESS databases. We then selected a subset of the dataset composed of 279 different mineral species, all of which are present in both the VNIR and LIBS datasets. In Table 5 we report accuracies of the compared methods averaged over 30 independent training runs.| Individual | Combined VNIR + LIBS | ||||
|---|---|---|---|---|---|
| Method | LIBS | VNIR | Ave-p | Mul-p | Sq-p |
| CNN + cosine | 15.75% | 73.01% | 77.49% | 77.24% | 79.04% |
| CNN + CNN | 9.31% | 78.53% | 78.14% | 79.34% | 78.14% |
4 Discussion
During our validation testing of ML techniques for analysing spectra from individual instruments, we developed a CNN solution for the classification of Raman spectra that significantly outperformed previous state-of-the-art methods. Crucially, we were then able to develop a novel approach for mineral classification that combines data obtained from three different spectroscopic methods that outperforms the use of a single type of spectroscopic data.It is important to note that the method which provided the highest accuracy when combining Raman + LIBS or VNIR + LIBS, was different from the most accurate method used to combine VNIR and Raman data. This result is related to the different algorithms used to estimate elemental composition from the LIBS spectra, and the different method used to fuse this information with the prediction of Raman or VNIR classifier (Fig. 3). Although the combination of Raman and VNIR achieved the highest mineral classification accuracy, this result could be affected by the differences in the available pair-combined spectral datasets. In general, the more spectroscopic information from different spectroscopic techniques available, the more reliable the derived classification.
The improvement in detection accuracy achieved by combining the Raman scattering and VNIR absorption spectra was predicted. These two types of the vibrational spectra are known to be complementary to each other by being excited by different and in some cases mutually exclusive vibrational transitions in molecules.57,58 The improvements in combining the chemical abundances (provided by LIBS) and mineralogical information (provided by Raman or VNIR) were also expected due to our experience and previous works, e.g., by Haavisto et al.,9 Khajehzadeh et al.,10 Sharma et al.,12 Rammelkamp et al.13 Our cross-validation tests quantitatively confirm those predictions and paves the way for potential real-time detection of minerals with two or more analytical methods combined in a single instrument.
For illustrative purposes, we demonstrate below the classification performance improvements in recognizing and distinguishing two end-members of the olivine solid solution series, Forsterite –Mg22+(SiO4)– versus Fayalite – Fe22+(SiO4). Olivines are important rock-forming minerals occurring in igneous rocks on terrestrial planets whose composition within the rocks would have implications for understanding the redox conditions and the degree of weathering.59 As can be seen on top spectra comparison plot of Fig. 6, olivines exhibit diagnostic absorption features across visible to near-infrared (VNIR) wavelengths due to the charge transitions of Fe2+, and Mg in its crystal structure, e.g., Isaacson et al.60
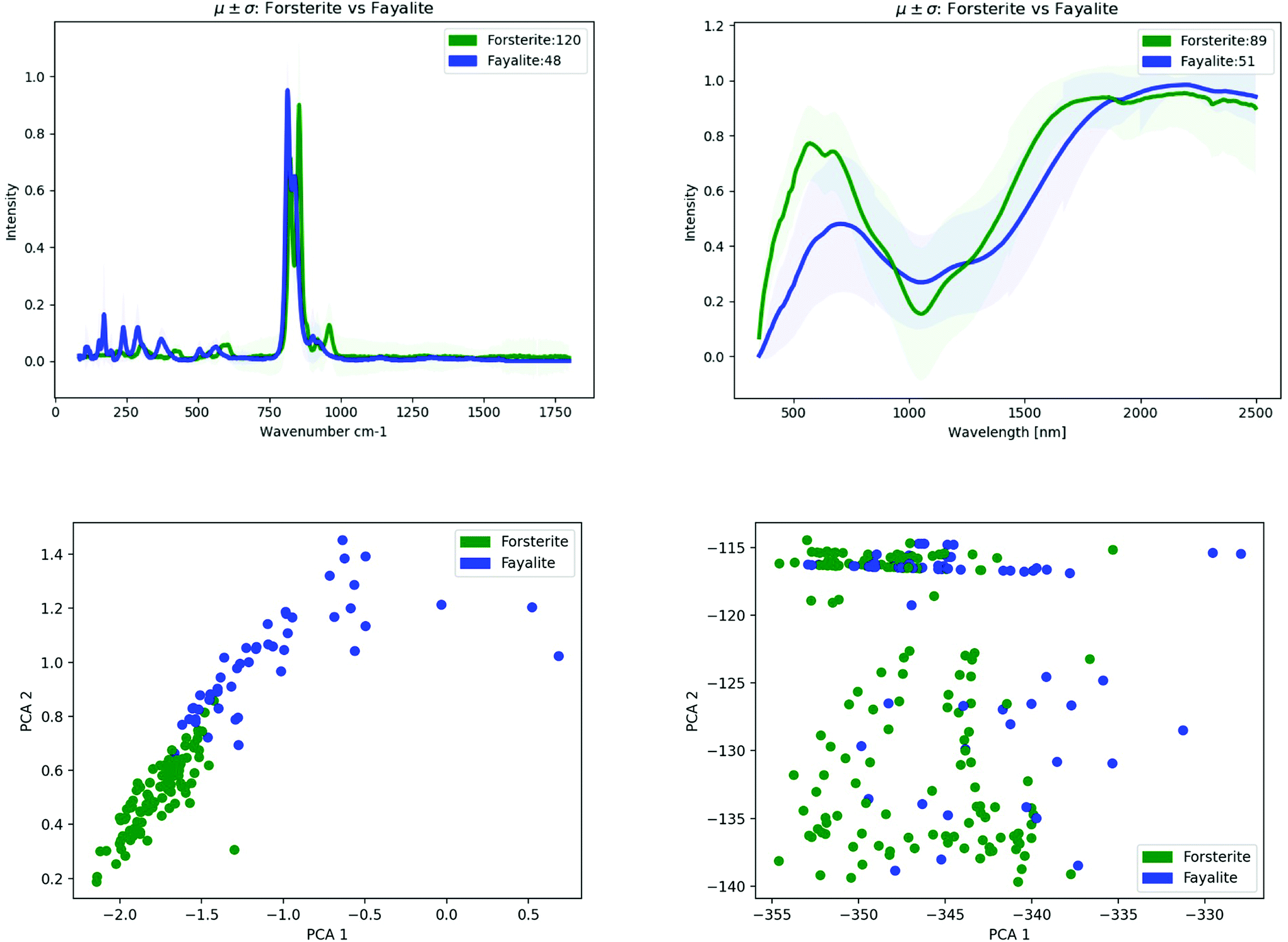 | ||
| Fig. 6 (Top row) Average and standard deviation of all available Raman & VNIR spectra for two end-members of the olivine solution series, Forsterite (shown in green) and Fayalite (shown in blue). (Bottom row) Scatter plot of two principal components in Raman and VNIR spectra of Forsterite (green filled circles) and Fayalite (blue filled circles). | ||
At the same time, the Raman spectra of the olivine-group minerals show a strong characteristic set of two intense lines of the Si–O asymmetric stretching band and Si–O symmetric stretching band, e.g., Mouri and Enami,61 Breitenfeld et al.62
Moreover, for both of the vibrational spectroscopic methods, the subtle changes in chemical composition could lead to recognizable modifications of their vibrational spectroscopic features. This can be seen on the simple Principle Component Analysis (PCA) shown on the two plots at the bottom of Fig. 6.
The combination of two or more analytical methods has the potential to improve classification accuracy across the olivine solid solution. This is again seen in the direct pair-combined spectra fusion (Fig. 7). However, the partial overlapping of the first and second principal components are present when combining mineral spectra at the data level (“lower level data fusion”) due to many variables that affect the spectra, including the mineral sample properties (grain size distribution, porosity), the specifics of spectrometer (e.g., the wavelength of energy used as a probe), data preprocessing (e.g. baseline removal) and environmental effects. Some of the above effects could plausibly be overlooked by the PCA lower-dimensional feature space (e.g., Carey et al.,27 Rammelkamp et al.13). The ML method detailed in this paper (Method 7: Ensemble of 6 architectures) results in average classification accuracy for Forsterite and Fayalite of about 80% based on their Raman spectra and about 20% based on their VNIR spectra, however when combined together Raman + VNIR spectra improve the average prediction score up to about 90%. The late fusion appears to work well even in our heterogenous spectroscopic data obtained with different spectrometers, various instrument calibrations, environmental conditions, and a broad type of mineral samples.
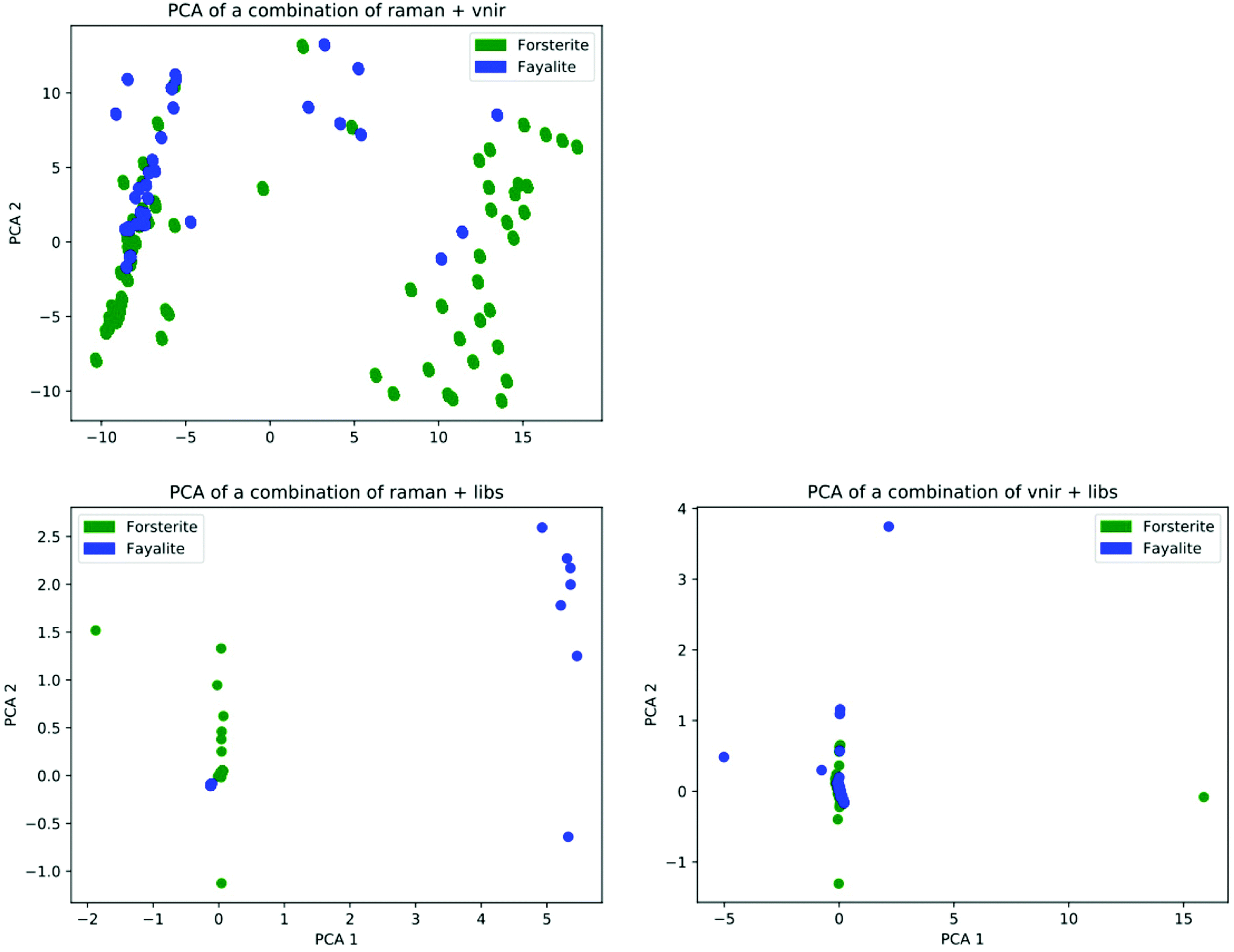 | ||
| Fig. 7 Scatter plot of two principal components for the pair-combined Raman + VNIR, Raman + LIBS and VNIR + LIBS spectra for Forsterite (green circles) and Fayalite (in blue). | ||
5 Conclusion
The results detailed in this paper demonstrate that ML techniques can successfully combine the results of two analytical instruments to improve mineral classification accuracy. Although the ML techniques deployed here require time and compute power during training, once trained they can run on portable battery powered hardware, such as commercially available off-the-shelf (COTS) tablets and laptops. This makes the technique ideal for deployment in remote locations where power and space is limited. With further development, these ML techniques can be applied to a range of terrestrial arenas, such as in the mining industry. However, it particularly holds promise for space applications. Deployable instrumentation for the next human exploration of the Moon and Mars should combine multiple spectroscopic techniques into as few devices as possible. Combining the results from these instruments in situ will help enable rapid decision support on sample collection priorities.Conflicts of interest
There are no conflicts to declare.Acknowledgements
P. J. would like to thank the CAVES & PANGAEA Team at the ESA/EAC for providing internship opportunity that resulted in this work. This research utilizes data from the following open-access repositories: RRUFF, RELAB, ECOSTRESS, USGS, NIST-LIBS and Webmineral. We would like to thank Dr C. J. Carey for sharing with us his version of the RRUFF Raman spectra, and Dr N. J. McMillan for sharing her LIBS spectral archive.Notes and references
- K. H. Beaton, S. P. Chappell, A. F. J. Abercromby, M. J. Miller, S. E. Kobs Nawotniak, A. L. Brady, A. H. Stevens, S. J. Payler, S. S. Hughes and D. S. S. Lim, Astrobiology, 2019, 19, 300–320 CrossRef.
- A. Sehlke, Z. Mirmalek, D. Burtt, C. W. Haberle, D. Santiago-Materese, S. E. Kobs Nawotniak, S. S. Hughes, W. B. Garry, N. Bramall, A. J. Brown, J. L. Heldmann and D. S. S. Lim, Astrobiology, 2019, 19, 401–425 CrossRef.
- P. E. Clark, R. L. Staehle, D. Bugby, A. Fraeman and R. O. Green, et al., in Lunar Surface Science Workshop, 2020, p. 2241 Search PubMed.
- D. F. Blake, in X-Ray Conference, 1999, pp. 1–11 Search PubMed.
- R. C. Wiens, S. Maurice, B. Barraclough, M. Saccoccio, W. C. Barkley, J. F. Bell, S. Bender, J. Bernardin, D. Blaney, J. Blank, M. Bouyé, N. Bridges, N. Bultman, P. Caïs, R. C. Clanton, B. Clark, S. Clegg, A. Cousin, D. Cremers, A. Cros, L. DeFlores, D. Delapp, R. Dingler, C. D'Uston, M. Darby Dyar, T. Elliott, D. Enemark, C. Fabre, M. Flores, O. Forni, O. Gasnault, T. Hale, C. Hays, K. Herkenhoff, E. Kan, L. Kirkland, D. Kouach, D. Landis, Y. Langevin, N. Lanza, F. LaRocca, J. Lasue, J. Latino, D. Limonadi, C. Lindensmith, C. Little, N. Mangold, G. Manhes, P. Mauchien, C. McKay, E. Miller, J. Mooney, R. v. Morris, L. Morrison, T. Nelson, H. Newsom, A. Ollila, M. Ott, L. Pares, R. Perez, F. Poitrasson, C. Provost, J. W. Reiter, T. Roberts, F. Romero, V. Sautter, S. Salazar, J. J. Simmonds, R. Stiglich, S. Storms, N. Striebig, J.-J. Thocaven, T. Trujillo, M. Ulibarri, D. Vaniman, N. Warner, R. Waterbury, R. Whitaker, J. Witt and B. Wong-Swanson, Space Sci. Rev., 2012, 170, 167–227 CrossRef.
- F. Rull, S. Maurice, I. Hutchinson, A. Moral, C. Perez, C. Diaz, M. Colombo, T. Belenguer, G. Lopez-Reyes, A. Sansano, O. Forni, Y. Parot, N. Striebig, S. Woodward, C. Howe, N. Tarcea, P. Rodriguez, L. Seoane, A. Santiago, J. A. Rodriguez-Prieto, J. Medina, P. Gallego, R. Canchal, P. Santamaría, G. Ramos, J. L. Vago and on behalf of the RLS Team, Astrobiology, 2017, 17, 627–654 CrossRef CAS.
- J.-P. Bibring, V. Hamm, C. Pilorget and J. L. Vago and MicrOmega Team, Special Collection of Papers: ExoMars Rover Mission, 2017 Search PubMed.
- R. C. Wiens, S. Maurice and F. Rull Perez, Spectroscopy, 2017, 32, 50–55 CAS.
- O. Haavisto, T. Kauppinen and H. Häkkänen, IFAC Proc. Ser., 2013, 46, 87–91 Search PubMed.
- N. Khajehzadeh, O. Haavisto and L. Koresaar, Miner. Eng., 2017, 113, 83–94 CrossRef CAS.
- T. Kauppinen, N. Khajehzadeh and O. Haavisto, Int. J. Miner. Process., 2014, 132, 26–33 CrossRef CAS.
- S. K. Sharma, A. K. Misra, P. G. Lucey and R. C. F. Lentz, Spectrochim. Acta, Part A, 2009, 73, 468–476 CrossRef.
- K. Rammelkamp, S. Schröder, S. Kubitza, D. S. Vogt, S. Frohmann, P. B. Hansen, U. Böttger, F. Hanke and H.-W. Hübers, J. Raman Spectrosc., 2020, 51, 1682–1701 CrossRef CAS.
- J. Schmidt, M. R. G. Marques, S. Botti and M. A. L. Marques, npj Comput. Mater., 2019, 5, 83 CrossRef.
- S. Geisser, Predictive Inference, Chapman and Hall/CRC, 1993 Search PubMed.
- R. Kohavi, in Proceedings of the 14th International Joint Conference on Artificial Intelligence, Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 1995, vol. 2, pp. 1137–1143 Search PubMed.
- T. Hastie, R. Tibshirani and J. Friedman, The Elements of Statistical Learning, Springer New York, New York, NY, 2009 Search PubMed.
- I. Drozdovskiy, G. Ligeza, P. Jahoda, M. Franke, P. Lennert, P. Vodnik, S. J. Payler, M. Kaliwoda, R. Pozzobon, M. Massironi, L. Turchi, L. Bessone and F. Sauro, Data Brief, 2020, 105985 CrossRef.
- F. Sauro, M. Massironi, R. Pozzobon, H. Hiesinger, N. Mangold, J. Martínez-Frías, C. Cockell and L. Bessone, in 49th Lunar and Planetary Science Conference, The Woodlands, Texas, USA, 2018 Search PubMed.
- I. Drozdovsky, E. Luzzi, F. Sauro, A. P. Rossi, M. Maurer, S. Payler, L. Bessone, M. Franke, P. Lennert and P. Vodnik, in EGU General Assembly 2019, 2019, vol. 21 Search PubMed.
- T. Cover and P. Hart, IEEE Trans. Inf. Theory, 1967, 13, 21–27 Search PubMed.
- S. T. Ishikawa and V. C. Gulick, Comput. Geosci., 2013, 54, 259–268 CrossRef.
- C. Cortes and V. Vapnik, Mach. Learn., 1995, 20, 273–297 Search PubMed.
- X. Cui, Z. Zhao, G. Zhang, S. Chen, Y. Zhao and J. Lu, Biomed. Opt. Express, 2018, 9, 4175 CrossRef CAS.
- P. Geurts, D. Ernst and L. Wehenkel, Mach. Learn., 2006, 63, 3–42 CrossRef.
- V. Sevetlidis and G. Pavlidis, J. Cult. Herit., 2019, 37, 121–128 CrossRef.
- C. Carey, T. Boucher, S. Mahadevan, P. Bartholomew and M. D. Dyar, J. Raman Spectrosc., 2015, 46, 894–903 CrossRef CAS.
- K. Fukushima, Biol. Cybern., 1980, 36, 193–202 CrossRef CAS.
- Y. LeCun, in Proceedings of Cognitiva 85, Paris, France, 1985, pp. 599–604 Search PubMed.
- J. Liu, M. Osadchy, L. Ashton, M. Foster, C. J. Solomon and S. J. Gibson, Analyst, 2017, 142, 4067–4074 RSC.
- P. Burkert, F. Trier, M. Z. Afzal, A. Dengel and M. Liwicki, ArXiv.
- K. Simonyan and A. Zisserman, arXiv 1409.1556.
- E. J. Bjerrum, M. Glahder, T. Skov, E. J. Bjerrum, M. Glahder and T. Skov, CoRR.
- B. Lafuente, R. T. Downs, H. Yang and N. Stone, in Highlights in Mineralogical Crystallography, ed. T. Armbruster and R. M. Danisi, DE GRUYTER, Berlin, München, Boston, 2015, pp. 1–30 Search PubMed.
- C. Carey, T. Boucher, T. Giguere, S. Mahadevan and M. D. Dyar, in In International joint conference on AI workshop on AI in space, 2015, pp. 20–27 Search PubMed.
- N. v Chawla, K. W. Bowyer, L. O. Hall and W. P. Kegelmeyer, J. Artif. Intell. Res., 2002, 16, 321–357 CrossRef.
- P. Larkin, Infrared and Raman Spectroscopy, Elsevier, 2nd edn, 2018 Search PubMed.
- I. Tomuta, A. Porfire, T. Casian and A. Gavan, in Calibration and Validation of Analytical Methods - A Sampling of Current Approaches, InTech, 2017, pp. 35–60 Search PubMed.
- K. Tanabe, H. Uesaka, T. Inoue, H. Takahashi and S. Tanaka, Bunseki Kagaku, 1994, 43, 765–769 CrossRef CAS.
- K. Parakh, S. Thakur, B. Chudasama, S. Tirodkar, A. Porwal and A. Bhattacharya, Multispectral, Hyperspectral, and Ultraspectral Remote Sensing Technology, Techniques and Applications VI, 2016, vol. 9880, p. 98801Z Search PubMed.
- S. Tanaka, H. Tsuru, K. Someno and Y. Yamaguchi, Geosciences, 2019, 9, 195 CrossRef CAS.
- C. Pieters and T. Hiroi and NASA Reflectance Experiment Laboratory, Lunar and Planetary Science XXXV, 2004, vol. 35, p. 1720 Search PubMed.
- R. F. Kokaly, R. N. Clark, G. A. Swayze, K. E. Livo, T. M. Hoefen, N. C. Pearson, R. A. Wise, W. M. Benzel, H. A. Lowers, R. L. Driscoll and A. J. Klein, U.S. Geol. Surv. Data Ser., 2017, 1035, 61 Search PubMed.
- S. K. Meerdink, S. J. Hook, D. A. Roberts and E. A. Abbott, Remote Sens. Environ., 2019, 230, 1–8 CrossRef.
- A. M. Baldridge, S. J. Hook, C. I. Grove and G. Rivera, Remote Sens. Environ., 2009, 113, 711–715 CrossRef.
- Y. Ralchenko and A. Kramida, Atoms, 2020, 8(3), 56 CrossRef.
- G. Amato, G. Cristoforetti, S. Legnaioli, G. Lorenzetti, V. Palleschi, F. Sorrentino and E. Tognoni, Spectrochim. Acta, Part B, 2010, 65, 664–670 CrossRef.
- Z. Ji, in Proceedings of the 2015 International Power, Electronics and Materials Engineering Conference, Atlantis Press, Paris, France, 2015 Search PubMed.
- C. Gohlke, molmass, https://pypi.org/project/molmass/ (accessed 3 June 2020).
- J. Chen, J. Pisonero, S. Chen, X. Wang, Q. Fan and Y. Duan, Spectrochim. Acta, Part B, 2020, 166, 105801 CrossRef CAS.
- L.-N. Li, X.-F. Liu, W.-M. Xu, J.-Y. Wang and R. Shu, Spectrochim. Acta, Part B, 2020, 169, 105850 CrossRef CAS.
- M. Ferus, J. Koukal, L. Lenža, J. Srba, P. Kubelík, V. Laitl, E. M. Zanozina, P. Váňa, T. Kaiserová, A. Knížek, P. Rimmer, E. Chatzitheodoridis and S. Civiš, Astron. Astrophys., 2018, 610, A73 CrossRef.
- K. Simonyan and A. Zisserman, in Proceedings of the 27th International Conference on Neural Information Processing Systems, MIT Press, Cambridge, MA, USA, 2014, vol. 1, pp. 568–576 Search PubMed.
- F. Chollet, et al., Keras, https://keras.io/api/layers/regularizers/, (accessed September 16, 2020).
- C. Feichtenhofer, A. Pinz and A. Zisserman, in 2016 {IEEE} Conference on Computer Vision and Pattern Recognition ({CVPR}), IEEE, 2016, pp. 1933–1941 Search PubMed.
- J. L. Hintze and R. D. Nelson, Am. Stat., 1998, 52, 181–184 Search PubMed.
- B. K. Sharma, Spectroscopy, Krishna Prakashan Media, 1981 Search PubMed.
- K. Hashimoto, V. R. Badarla, A. Kawai and T. Ideguchi, Nat. Commun., 2019, 10, 4411 CrossRef.
- M. D. Dyar, E. C. Sklute, O. N. Menzies, P. A. Bland, D. Lindsley, T. Glotch, M. D. Lane, M. W. Schaefer, B. Wopenka, R. Klima, J. L. Bishop, T. Hiroi, C. Pieters and J. Sunshine, Am. Mineral., 2009, 94, 883–898 CrossRef CAS.
- P. Isaacson, R. Klima, J. Sunshine, L. Cheek, C. Pieters, T. Hiroi, M. Dyar, M. Lane and J. Bishop, Am. Mineral., 2014, 99, 467–478 CrossRef.
- T. Mouri and M. Enami, J. Mineral. Petrol. Sci., 2008, 103, 100–104 CrossRef CAS.
- L. B. Breitenfeld, M. D. Dyar, C. J. Carey, T. J. Tague, P. Wang, T. Mullen and M. Parente, Am. Mineral., 2018, 103, 1827–1836 CrossRef.
Footnotes |
| † European Space Agency Intern. |
| ‡ i.e., the ratio of number of correct predictions to the total number of input samples. |
| This journal is © The Royal Society of Chemistry 2021 |