
 Open Access Article
Open Access Article This Open Access Article is licensed under a
This Open Access Article is licensed under a Creative Commons Attribution 3.0 Unported Licence
Improving reconstructions in nanotomography for homogeneous materials via mathematical optimization†
Sebastian
Kreuz
a,
Benjamin
Apeleo Zubiri
 *b,
Silvan
Englisch
b,
Moritz
Buwen
b,
Sung-Gyu
Kang
cd,
Rajaprakash
Ramachandramoorthy
c,
Erdmann
Spiecker
b,
Frauke
Liers
a and
Jan
Rolfes
*a
*b,
Silvan
Englisch
b,
Moritz
Buwen
b,
Sung-Gyu
Kang
cd,
Rajaprakash
Ramachandramoorthy
c,
Erdmann
Spiecker
b,
Frauke
Liers
a and
Jan
Rolfes
*a
aDepartment of Data Science, Friedrich-Alexander-Universität Erlangen-Nürnberg, Cauerstr. 11, 91058 Erlangen, Germany. E-mail: jan.rolfes@fau.de
bInstitute of Micro- and Nanostructure Research (IMN) & Center for Nanoanalysis and Electron Microscopy (CENEM), Department of Materials Science and Engineering, Friedrich-Alexander-Universität Erlangen-Nürnberg, Cauerstr. 3, 91058 Erlangen, Germany. E-mail: benjamin.apeleo.zubiri@fau.de
cDepartment Structure and Nano- / Micromechanics of Materials, Max-Planck-Institut für Eisenforschung GmbH, Max-Planck-Str. 1, 40237 Düsseldorf, Germany. E-mail: r.ram@mpie.de
dDepartment of Materials Engineering and Convergence Technology, Gyeongsang National University, Jinju-daero 501, 52828 Jinju, Republic of Korea
First published on 3rd June 2024
Abstract
Compressed sensing is an image reconstruction technique to achieve high-quality results from limited amount of data. In order to achieve this, it utilizes prior knowledge about the samples that shall be reconstructed. Focusing on image reconstruction in nanotomography, this work proposes enhancements by including additional problem-specific knowledge. In more detail, we propose further classes of algebraic inequalities that are added to the compressed sensing model. The first consists in a valid upper bound on the pixel brightness. It only exploits general information about the projections and is thus applicable to a broad range of reconstruction problems. The second class is applicable whenever the sample material is of roughly homogeneous composition. The model favors a constant density and penalizes deviations from it. The resulting mathematical optimization models are algorithmically tractable and can be solved to global optimality by state-of-the-art available implementations of interior point methods. In order to evaluate the novel models, obtained results are compared to existing image reconstruction methods, tested on simulated and experimental data sets. The experimental data comprise one 360° electron tomography tilt series of a macroporous zeolite particle and one absorption contrast nano X-ray computed tomography (nano-CT) data set of a copper microlattice structure. The enriched models are optimized quickly and show improved reconstruction quality, outperforming the existing models. Promisingly, our approach yields superior reconstruction results, particularly when only a small number of tilt angles is available.
1 Introduction
Projection-based nanotomography techniques, including electron tomography (ET), nano X-ray computed tomography (nano-CT) and micro X-ray computed tomography (micro-CT), are designed to gain three-dimensional (3D) information from a series of two-dimensional (2D) projections of an object on a nm to mm scale.1–3 The object, called sample or specimen, is placed on a sample holder between a typically stationary X-ray or electron beam source and a detector array in a transmission electron microscope or X-ray microscope. The projections encode information on interaction of the initial beam while penetrating through the sample. To obtain easily interpretable and reconstructable contrast, the measured intensities should exhibit a monotonic relationship to specific sample properties such as local density (i.e., mass attenuation) and thickness. In ET, this can be realized by using the so-called high-angle annular dark-field (HAADF) scanning transmission electron microscopy (STEM) imaging mode,4 whereas in nano- and micro-CT measurements, this is the case using the absorption contrast mode.5,6 In all cases, the sample holder or stage is tilted to perform projections from different tilt angles of the object. A visual representation of this process is depicted in Fig. 1. Mathematically, the projections can be modeled as an idealized, noiseless system of linear equations| Rf = p, | (1) |
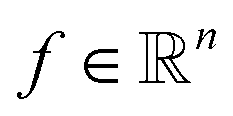 denotes the pixel brightness,
denotes the pixel brightness, 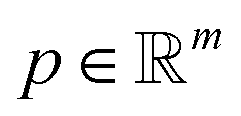 the projection data and the matrix
the projection data and the matrix 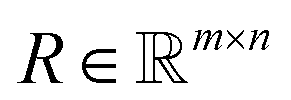 a discretized variant Radon transform. To be more precise, each row of R corresponds to a single projection ray. An entry of a row displays how much of a pixel is passed by the ray in relation to its side length. Multiple projection geometries including parallel, fan, and cone beams can be modeled in this way.7 However, as (1) describes an idealized setting, introducing uncertainties, such as noise, potentially render (1) infeasible.
a discretized variant Radon transform. To be more precise, each row of R corresponds to a single projection ray. An entry of a row displays how much of a pixel is passed by the ray in relation to its side length. Multiple projection geometries including parallel, fan, and cone beams can be modeled in this way.7 However, as (1) describes an idealized setting, introducing uncertainties, such as noise, potentially render (1) infeasible.
 | ||
| Fig. 1 Principle of projection-based nanotomography: a tilt series of projections from an object is acquired and, after an alignment with respect to the common tilt axis, the reconstruction of the object is calculated. | ||
Therefore, image reconstruction is usually performed via error minimization:
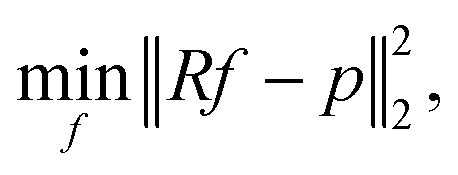 | (2) |
 , can be solved efficiently to global optimality with, e.g., gradient-based methods. In this work, we focus on the realistic and very natural setting where only few projections of the sample can be acquired. This is true, e.g., if projections are expensive, time-consuming or if beam-sensitive materials are studied, which can only withstand a certain X-ray or electron dose. Under these conditions, it is crucial to take only a small number of projections, the fewer the better. Few projections lead to m ≪ n. As a result, the linear equation system (1) is highly underdetermined and, consequently, the information is highly undersampled.
, can be solved efficiently to global optimality with, e.g., gradient-based methods. In this work, we focus on the realistic and very natural setting where only few projections of the sample can be acquired. This is true, e.g., if projections are expensive, time-consuming or if beam-sensitive materials are studied, which can only withstand a certain X-ray or electron dose. Under these conditions, it is crucial to take only a small number of projections, the fewer the better. Few projections lead to m ≪ n. As a result, the linear equation system (1) is highly underdetermined and, consequently, the information is highly undersampled.
Established iterative reconstruction techniques to solve (2) are, e.g., the simultaneous algebraic reconstruction technique (SART)8 and the simultaneous iterative reconstruction technique (SIRT).9,10
Compressed sensing (CS), also named compressive sensing or compressive sampling, is a thoroughly studied signal processing technique to achieve improved reconstructions from such undersampled information by using prior knowledge about the reconstructed signal. In particular, considering the potential sparsity of the underlying signal in a known transform domain can crucially improve the reconstruction as was demonstrated in the seminal paper of Candès et al.11 CS has a wide range of applications, see, e.g., Qaisar et al.12 To this end, compressed sensing is often combined with a regularization term such as high order total variation (HOTV),13 wavelets,14 total generalized variation (TGV)15 and total variation (TV) regularization.16 Leary et al.16 provide numerical results specifically for nanotomography and solves the resulting modified CS with a conjugate gradient descent algorithm. It thus serves as our second benchmark apart from a simple SIRT approach that solves (2) directly. In addition, other image reconstruction techniques such as total variation regularized discrete algebraic reconstruction technique (TVR-DART)7 aim to steer the solution to discrete gray values while also minimizing the total variation. Since TVR-DART is a well-established tool, we use it as benchmark as well.
The mathematical reconstruction scheme of CS is described in Section 2. This work aims at improving this scheme by incorporating prior knowledge about the sample as additional constraint classes. The goal is to reduce artifacts and achieve better reconstruction quality in case of undersampled information. Two such classes of constraints are individually derived and explained in Section 3. On the one hand, they consist in the algebraic formulation of strict upper bounds for pixel intensities that eliminate artifacts outside of the reconstructed samples. On the other hand, we also introduce soft upper bounds for pixel intensities with which deviations above a certain value can be penalized. This latter constraint class is applicable to homogeneous samples that are composed of only one material density and exploits this problem-specific fact to increase reconstruction quality. Hence, the CS algorithm including these additional constraints will be referred to as compressed sensing for homogeneous materials (CSHM). For an optimal exploitation of these constraints, the parameter selection is crucial and is therefore illustrated in Section 4 along with our benchmark algorithms. To evaluate the practical impact of the new constraint classes, they are applied to one simulated and two experimental data sets, one acquired with electron tomography, the other with nano-CT (see Section 5). The results are shown in Section 6, where comparisons to existing state-of-the-art algorithms are performed. It turns out that the new model leads to high-quality reconstructions within short time when compared to existing models, in particular, if only a few number of projections are available. A discussion of the results and some future extensions and applications are given in Section 7.
2 Compressed sensing framework
The following description of the CS framework is based on Leary et al.16 The first major assumption in CS is that there exists a known basis transformation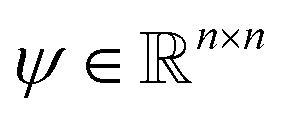 of the vector f, that is to be recovered, to a vector
of the vector f, that is to be recovered, to a vector  with m ≪ n nonzero coefficients ci. In this case, we say that the image f is compressible in ψ. Consequently, it suffices to only gather information in the compressed form, i.e., instead of recording samples of f directly, one records well-chosen samples bi of linear combinations
with m ≪ n nonzero coefficients ci. In this case, we say that the image f is compressible in ψ. Consequently, it suffices to only gather information in the compressed form, i.e., instead of recording samples of f directly, one records well-chosen samples bi of linear combinations 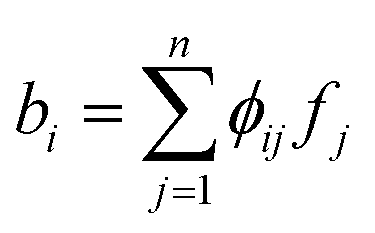 . Here,
. Here, 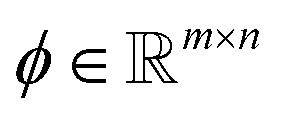 denotes known sampling coefficients, which are often inherent to the respective application, e.g., in a tomographic experiment, the measurements b denote the value of line integrals with respect to projected lines through the sample, whereas the lines itself are defined by ϕ.
denotes known sampling coefficients, which are often inherent to the respective application, e.g., in a tomographic experiment, the measurements b denote the value of line integrals with respect to projected lines through the sample, whereas the lines itself are defined by ϕ.
The second assumption in CS is that in order to recover f efficiently, one requires the matrices ψ and ϕ to be rather dissimilar. Similar matrices lead to redundant constraints c = ψf, b = ϕf and add little value by the measurements b as most of the coefficients bi are close to zero. To this end, one measures the dissimilarity or incoherence of ψ and ϕ. In the present paper, as well as in other nanotomography applications, incoherency with respect to the sensing matrix R and the transforming matrix ψ is controlled by the measuring process. Using, e.g., HAADF-STEM imaging, incoherency is ensured by the independence of the different scanning position measurements.17 With these two requirements, a reconstruction scheme, enforcing both sparsity in the transform domain and data consistency with the measurements, can be formulated. In particular, given the lp norm for 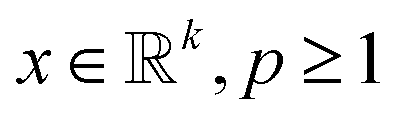 defined by
defined by
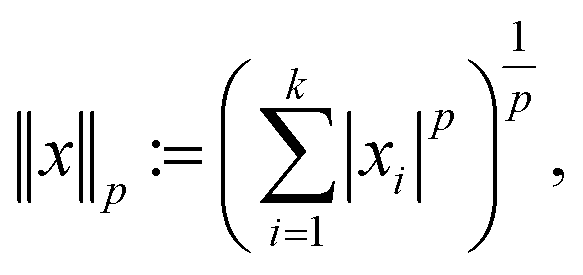
we focus on the Basis pursuit denoising (BPD) model introduced by Chen et al.18 for image reconstruction. For a broader overview on BPD as well as other image reconstruction models, we refer to the seminal book of Foucart and Rauhut.19 In BPD, data consistency is enforced by penalizing deviations in the objective function, where λ ≥ 0 weighs the sparsity
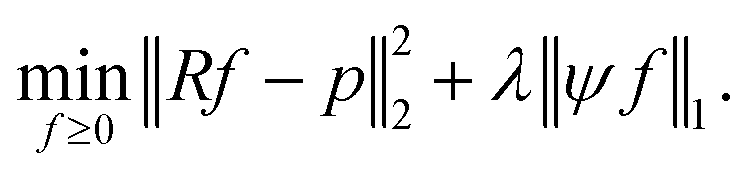 | (3) |
Measuring the sparsity of ψf directly via the non-convex l0 norm, defined by ‖x‖0 ≔ |{i: xi ≠ 0}|, generally leads to a more complex problem (3). Instead, the l1 norm is applied, to ensure sufficient sparsity, ideally restricting ψf to at most as many non-zero components as the number of projections m.20 The BPD problem formulation (3) is widely used in the literature, e.g., in Lustig et al.14 or in Block et al.21
The main focus of this work lies in the reconstruction of homogeneous materials. The latter are of frequent interest in nanotomography, such as in the 3D investigation of porous supports for applications in heterogeneous catalysis,22 particle chromatography,23 fuel cells24 or battery electrodes.25 For homogeneous materials, reconstruction algorithms based on combinatorial optimization models have been presented in Liers and Pardella.26 Since homogeneous materials consist of only one approximately constant density value (i.e., composition or material phase), they provide additional information that is known beforehand. In particular, being composed of only one density value, these reconstructions are expected to exhibit either areas of said density or empty space (typically filled with vacuum or air), with only a few sharp edges in between. This promotes sparsity in its spatial finite differences. Exploiting this sparsity with compressed sensing is called total variation (TV) minimization and is often applied in the literature, e.g., by Sidky and Pan27 or Leary et al.16 It uses the a priori knowledge that most pixels are surrounded by pixels of the same grey level.
For a quadratic picture with n = l2 pixels, the sparsifying TV transform ψTV ∈ {−1, 0, 1}2(n−l)×n is indirectly defined like in Block et al.21 by:
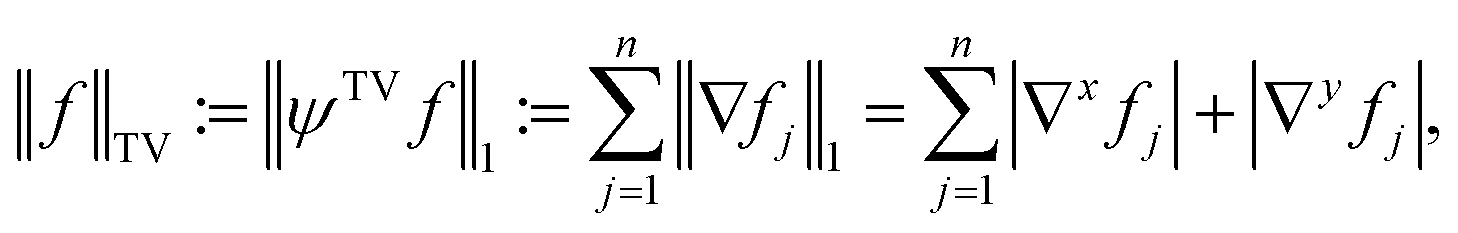 | (4) |
| ∇fj := (∇xfj, ∇yfj), | (5a) |
 | (5b) |
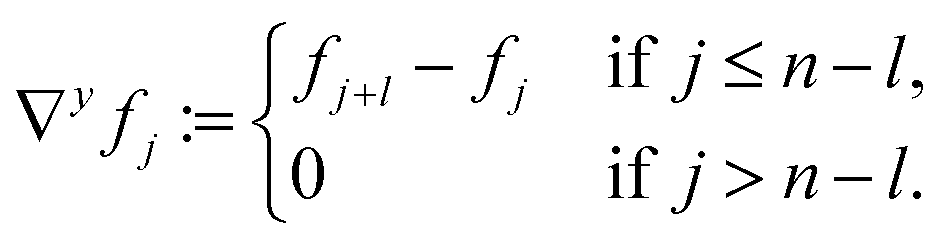 | (5c) |
For solving the CS optimization problems, several efficient algorithms are known, such as interior point methods (IPM),28 conjugate gradient methods16 as well as multiple heuristic approaches like ASD-POCS.27
2.1 TVR-DART
We revisit the TVR-DART algorithm, developed by Zhuge et al.,7 which is an image reconstruction technique specifically developed for samples consisting of only a few different density values. It combines the ideas of compressed sensing and discrete tomography. Homogeneous samples in nanotomography are one of many applications. We use the image reconstructions computed by this algorithm as a benchmark later in Section 6.TVR-DART starts with estimating parameters by means of a SIRT reconstruction. Then the following optimization problem is solved
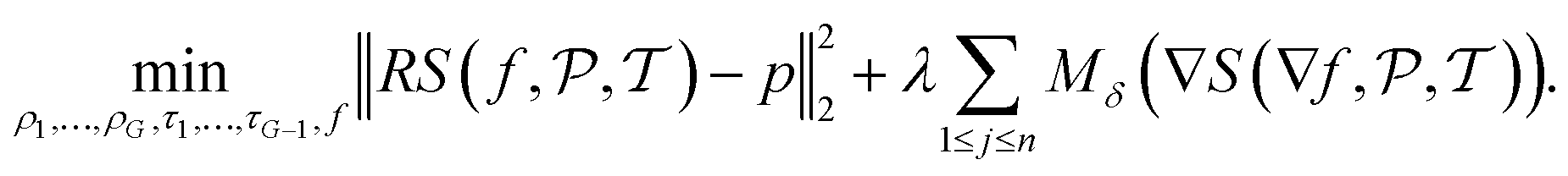 | (6) |
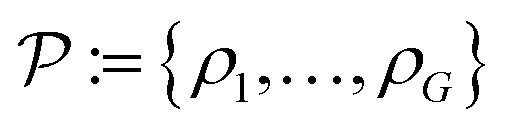 . The number of density values, G ≥ 1, is assumed to be known in advance. τ1, …, τG−1 are the thresholds between the density values
. The number of density values, G ≥ 1, is assumed to be known in advance. τ1, …, τG−1 are the thresholds between the density values  , setting the turning points of when a pixel density is pushed to either the lower or the higher density value. This is done by applying a differentiable soft segmentation function S to each individual pixel density fj. The function smoothly drives them towards the values in
, setting the turning points of when a pixel density is pushed to either the lower or the higher density value. This is done by applying a differentiable soft segmentation function S to each individual pixel density fj. The function smoothly drives them towards the values in 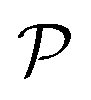 . The optimization problem (6) is now solved for the smooth image
. The optimization problem (6) is now solved for the smooth image 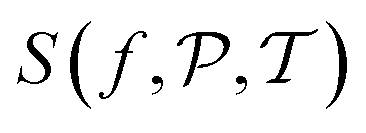 . Zhuge et al.7 chose S as a smooth approximation of a piecewise constant staircase function with values in
. Zhuge et al.7 chose S as a smooth approximation of a piecewise constant staircase function with values in  and jumps in
and jumps in  . Instead of using the TV-norm for the sparsity term as in usual TV minimization, a differentiable norm is suggested using a Huber loss function Mδ with δ = 10−4.
. Instead of using the TV-norm for the sparsity term as in usual TV minimization, a differentiable norm is suggested using a Huber loss function Mδ with δ = 10−4.
Although the formulation is natural, it comes with the computational complexity that (6) is an unconstrained continuous however non-convex optimization problem. Zhuge et al. use an alternating heuristic minimization procedure to find solutions in a short amount of time, starting with an initial reconstruction produced by SIRT. While TVR-DART often appears effective in practical scenarios, its authors acknowledge its divergence under specific conditions, implying the absence of a guaranteed high-quality solution. This behavior is common when aiming to solve non-convex optimization problems through local heuristics. In order to avoid these drawbacks, the newly introduced compressed sensing extensions of this work are all convex, enabling the utilization of efficient interior point methods.
3 Incorporating problem specific information
In this section, we introduce model extensions to increase the quality of the reconstructed images. They counteract different kinds of artifacts that typically appear in image reconstructions. In the following, the terms hard and soft upper bounds are used. Hard bounds mean bounds on variables that are enforced by a constraint and cannot be violated in a solution. Soft bounds, on the contrary, are bounds on variables that are not enforced but promoted by penalizing violations in the objective function weighted by an appropriately chosen parameter.3.1 Hard upper bound on f in image reconstruction
With (1), i.e., assuming perfect projections without noise, it holds that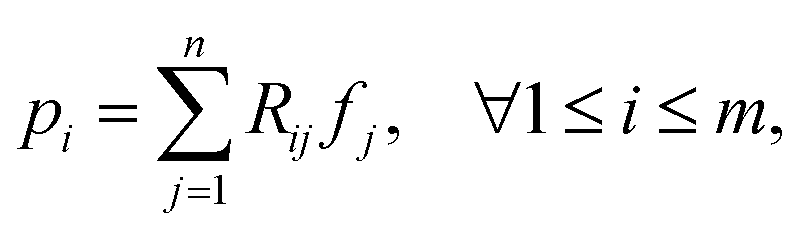 | (7) |
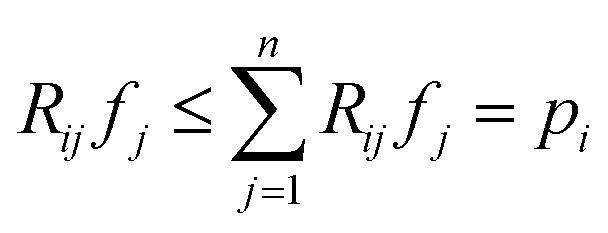 and thus the following variable bound emerges:
and thus the following variable bound emerges: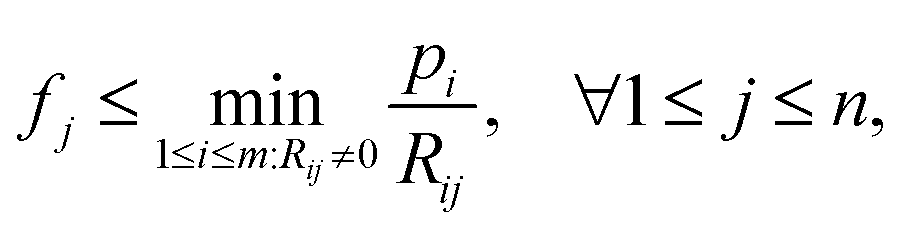 | (8) |
We note that on the one hand, the bound 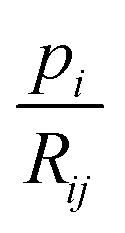 is loose for rays i that pass through multiple sample-containing pixels j. This then causes the projection value
is loose for rays i that pass through multiple sample-containing pixels j. This then causes the projection value 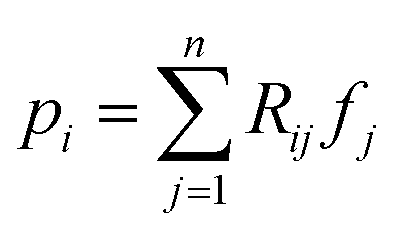 to be large. However, on the other hand, it is advantageous for rays that hit no sample pixels. Indeed, they have a rather small projection value pi. As a consequence, all pixels passed by such a ray are restricted by a very tight bound (8). This nudges the algorithm towards reconstructions that correctly consider little to no material at these pixels, even if that would be beneficial for the overall error minimization. Hence, the algorithm provides reduced undersampling artifacts (e.g., streaking artifacts) outside of the reconstructed sample, assuming the sample does not fill out the whole field of view of the microscope or detector and that the sample is surrounded only by air or vacuum. This effect is observed in the results later in Section 6. We note that the impact of (8) is dependent on the average noise level of the background – the higher the noise level, the looser the bounds. Therefore, a mean background noise subtraction preprocessing step should be applied before reconstruction.
to be large. However, on the other hand, it is advantageous for rays that hit no sample pixels. Indeed, they have a rather small projection value pi. As a consequence, all pixels passed by such a ray are restricted by a very tight bound (8). This nudges the algorithm towards reconstructions that correctly consider little to no material at these pixels, even if that would be beneficial for the overall error minimization. Hence, the algorithm provides reduced undersampling artifacts (e.g., streaking artifacts) outside of the reconstructed sample, assuming the sample does not fill out the whole field of view of the microscope or detector and that the sample is surrounded only by air or vacuum. This effect is observed in the results later in Section 6. We note that the impact of (8) is dependent on the average noise level of the background – the higher the noise level, the looser the bounds. Therefore, a mean background noise subtraction preprocessing step should be applied before reconstruction.
As already stated, (7) holds for many projection geometries, making the proposed bounds (8) applicable to a broad range of different tomography image reconstruction problems. In particular, the bounds can also be easily implemented in the SIRT algorithm, in the same manner as non-negativity constraints, which are common practice. This was tested for this work as well, but the effects were neglectable. For the sake of completeness, an evaluation of the bounds to SIRT is provided in the ESI.†
3.2 Soft upper bound on f for homogeneous materials
Contrary to the hard upper bound (8), the following class of constraints describes suitable bounds for sample pixels, assuming a constant material density over the whole sample. In materials science, such homogeneous samples occur frequently. For the following bounds, we assume such a homogeneous sample with the single density value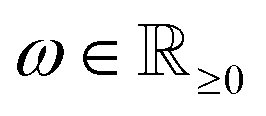 . If ω is not known in advance, it can be estimated. This can be done efficiently by reconstructing the same sample at a lower resolution and calculating a mean of all (bigger) positive values.
. If ω is not known in advance, it can be estimated. This can be done efficiently by reconstructing the same sample at a lower resolution and calculating a mean of all (bigger) positive values.
The idea of the constraints is to quadratically penalize the density values that exceed ω. Therefore, we define an auxiliary variable vector  and add the constraints
and add the constraints
| dj ≥ fj − ω, ∀1 ≤ j ≤ n, | (9) |
| dj ≥ 0, ∀1 ≤ j ≤ n, | (10) |
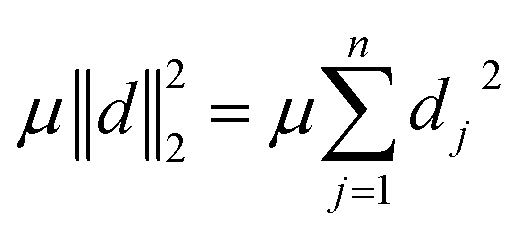 | (11) |
As a result of the quadratic formulation, the higher the reconstructed intensity of a pixel is above the density ω, thus being a potential artifact, the more it is penalized. This leads to a reconstructed image with fewer large deviations above ω, so that the density values tend to be comparable over the whole sample. A possible downside of this model is that projection artifacts, e.g., non-linear contrast effects like remaining Bragg contrast contributions in HAADF-STEM imaging of crystalline specimen, which otherwise would be reconstructed as a brighter spot in the material, could now be wrongly distributed onto other pixels. Especially feature edges, e.g., pore edges, are prone to receive such material, since in undersampled data, the placement of edges is not always clear. The here proposed soft constraints can thus potentially lead to decreasing pore sizes in porous specimen. However, the quadratic nature of the penalty keeps this effect small. These effects can be observed later in Section 6 and are further discussed in the ESI† on analyzed local thickness maps and pore size distributions of the differently reconstructed slices.
Next, we go one step further and discuss the usage of more advanced modelling techniques from mathematical optimization. One could argue that, if homogeneous samples contain only two pixel density values, 0 and ω, density values of f in the space between 0 and ω have to be penalized as well. In principle, this can be accomplished by the class of constraints
| dj ≥ |fj − ωbj|, ∀1 ≤ j ≤ n, | (12) |
| bj ∈ {0, 1}, ∀1 ≤ j ≤ n. | (13) |
Consequently, all pixel values are moved towards either 0 or ω, with small differences allowed if they lead to better data consistency or smaller spatial finite differences. Edge pixels, where only a fraction of a pixel contains material and the rest is background, which are usually present in experimental data, contradict the idea of (12) and (13). However, the higher the resolution, the less proportion of such pixels exist, so this drawback can be considered as neglectable for high-resolution images. Despite their modelling strengths, including binary variables significantly increases the problem's complexity. These variable turn the problem into a mixed-integer quadratic program (MIQP), which is NP-hard in general, i.e., it is widely expected to not be efficiently solvable. In particular, this makes the problem considerably more difficult than the original convex quadratic program.
Applying a linear or semidefinite programming (SDP) relaxation to the binary variables (13) leads to an equivalent reformulation of the soft upper bounds (9) and (10). The question if stronger relaxations can increase reconstruction quality further remains an interesting research question. In the remainder of this article however, we focus on (9) and (10) and postpone algorithms involving binary variables or stronger relaxations of those to future research.
In the following, we thus consider model
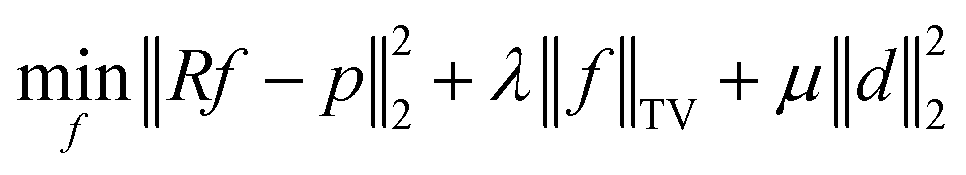 | (14a) |
| dj ≥ fj − ω, ∀1 ≤ j ≤ n, | (14b) |
| dj ≥ 0, ∀1 ≤ j ≤ n, | (14c) |
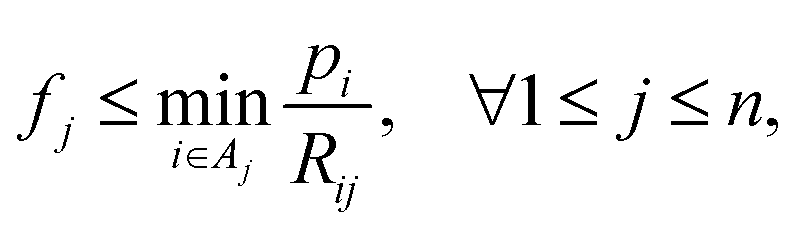 | (14d) |
| fj ≥ 0, ∀1 ≤ j ≤ n. | (14e) |
This problem will be referred to as compressed sensing for homogeneous materials (CSHM) because it exploits the homogeneity of the sample.
4 Algorithmic details
In this work, we focus on two-dimensional (2D) image reconstructions. For a parallel beam geometry and single tilt axis tomography experiments, 3D problems can be split into independent 2D problems, making the proposed optimization problem applicable by consecutively running it for 2D data.The new proposed reconstruction scheme was implemented in Python. It utilizes the ASTRA Toolbox, developed by Van Aarle et al.29 and the TVR-DART Toolbox, developed by Zhuge et al.7 For solving the CS problem (14), a state-of-the-art primal-dual interior point method (IPM), or barrier method30 (Gurobi 10.0.0) is used. A main advantage of an IPM consists in the fact that it can very efficiently solve large-sized, linearly constrained optimization problems with convex quadratic objective functions which is exactly the form of (14).
4.1 Selection of parameters
The objective function parameters of (14), λ and μ, have to be chosen beforehand. Here, λ, in the following λCS, is the weight of the total variation and μ the penalty for exceeding the mean density ω. This is somewhat similar to TVR-DART (6), where the parameter λ, in the following denoted by λTVR, has to be chosen as well.Several proposals in the literature for choosing λCS, e.g., by Chen et al.18 or Jin and Rao,31 did not lead to satisfying results. For reasons of simplicity, λCS was thus empirically chosen in the implementation of this work. The projection data sets showed the property that λCS can be chosen independently of pixel size or number of projection angles and yet perform well (not always optimal) for all 2D slices of a data set. The fact that λCS does not have to be increased with the number of projection angles or image pixels, despite the increasing error minimization term, can be interpreted in the following way. First, with more image pixels and thus higher resolution, or more information about the picture through more projection angles, the quality of images returned by only error minimization of (2) increases, and the undersampling artifacts decrease. A regularizing term λCS‖f‖TV, which is counteracting the undersampling artifacts, is needed less and less.
Furthermore, the two new constraints introduce an additional smoothing effect. The soft upper bounds penalize bright spots that show bigger densities than material density ω and push the exceeding material to other pixels. Those other pixels are lying inside the sample because the hard upper bounds enforce pixels outside of the sample to be 0 (or nearly 0). This smoothes the reconstructed sample. In this implementation, the parameter was empirically chosen as λCS = 20![[thin space (1/6-em)]](https://www.rsc.org/images/entities/char_2009.gif) 000 for the simulated, λCS = 4000 for the ET data set of the zeolite particle, and λCS = 3 for the nano-CT acquisition of the copper microlattice.
000 for the simulated, λCS = 4000 for the ET data set of the zeolite particle, and λCS = 3 for the nano-CT acquisition of the copper microlattice.
The parameter μ in (14a) specifies the weight of the penalty for exceeding ω with pixel densities fj. Since more projection angles or a higher pixel count generally does not lead to an increasing error term ‖d‖22, but ω-exceeding artifacts remain (in contrast to undersampling artifacts), μ has to be scaled correspondingly.
In X-ray and electron microscopy imaging, ω-exceeding artifacts may occur due to non-linear contrast relationships between measured intensity and the specimen's mass and thickness (i.e., local mass attenuation coefficients) caused by, e.g., non-linear mass-thickness contrast4 or remaining Bragg scattering effects32,33 in HAADF-STEM imaging.
Thus, in order to keep our penalty μ‖d‖22 relevant with increasing problem size and corresponding increasing reconstruction error term ‖Rf − p‖22, we scale μ with the problem size as follows:
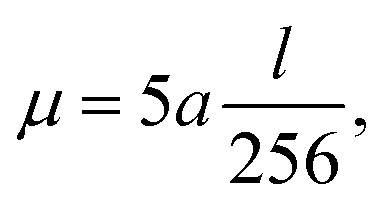 | (15) |
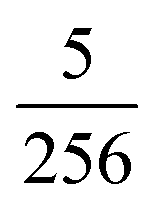 was empirically chosen as it produced good results in preliminary tests.
was empirically chosen as it produced good results in preliminary tests.
The authors Zhuge et al.7 suggest to choose the TVR-DART penalization parameter λTVR ∈ [10, 100]. However, this did not produce the visually best results, so instead the parameter is also chosen empirically for TVR-DART in order to guarantee a fair comparison. The chosen values are depicted below the reconstructions.
4.2 Reconstruction benchmark and hardware
To evaluate the quality of the developed constraints in CSHM, it is compared to three existing reconstruction techniques, namely SIRT (with enforced positivity in each step), CS and TVR-DART. Here, CS refers to the solution of (3) with TV minimization of (4) and no additional constraints, using the same IPM as CSHM. The IPM is run with a solution tolerance of 10−6. The number of iterations that the comparison algorithms SIRT and TVR-DART are supposed to perform when reconstructing images are set to 1000 for SIRT and 250 for TVR-DART. The initial SIRT reconstruction, which TVR-DART uses as a starting point, also runs for 1000 iterations. Note that TVR-DART can also terminate earlier by fulfilling a convergence stopping criterion before reaching the maximum number of iterations.All following image reconstructions presented in Section 6 were performed on a laptop computer with 16 GB RAM, an AMD Ryzen 9 5900HX with Radeon Graphics, 3301 MHz, 8 CPU cores, and 16 logical processors. For a GPU-accelerated version of SIRT, a NVIDIA GeForce RTX 3050 Laptop GPU was used.
5 Experimental details
Image reconstructions considered in this article are performed on three data sets: one simulated phantom object slice (Fig. 4a) with added random Poisson noise and two experimental data sets, one acquired by ET and one by nano-CT.The ET data in Fig. 2 comprises a macroporous MFI-type zeolite particle synthesized by Machoke et al.34 A full tilt series, as shown in SI Video 1,† in a tilt-angle range of 180° with 1° tilt increment (in total 180 projections) of the particle on top of the plateau of a tomography tip (so-called 360°-ET or on-axis ET) was acquired using a FEI Titan3 80–300 transmission electron microscope operated at an acceleration voltage of 200 kV in HAADF-STEM imaging mode (image size 1024 pixels × 1024 pixels; pixel size 3.55 nm) and a Fischione Model 2050 On-Axis Rotation Tomography sample holder (E.A. Fischione Instruments, Inc.). HAADF-STEM imaging assures an approximately parallel beam geometry and a monotonous relationship between measured intensities, sample mass (density), and thickness, so that the Radon transform can be applied for reconstruction. For more experimental details, please refer to Przybilla et al.35
 | ||
| Fig. 2 Exemplary projections of experimental ET data from different projection angles of a macroporous zeolite particle on the plateau of a tomography tip: (a) 20°, (b) 90°, (c) 160°. See SI Video 1† for an animation of the full tilt series. | ||
The nano-CT data set in Fig. 3 shows a copper microlattice. These copper microlattices were manufactured using an additive micromanufacturing technique based on localized electrodeposition in liquid (CERES system – Exaddon AG, Switzerland).36,37 The electrochemical ink required for the electrodeposition is supplied with a hollow atomic force microscope (AFM) cantilever with a small orifice (∼300 nm) and the metal ions get reduced on the conductive substrate that acts as the working electrode. Copper microlattices were built in a voxel-by-voxel manner using precise piezo positioners which move the AFM cantilever after each voxel deposition to a new location based on the deflection of the AFM cantilever sensed using a laser based optical tracking system.
 | ||
| Fig. 3 Exemplary projections of experimental absorption-contrast nano-CT data set from different projection angles of a copper microlattice structure: (a) 0°, (b) 10°, (c) 30°. See SI Video 2† for an animation of the full tilt series. | ||
The nano-CT experiment was performed using a ZEISS Xradia 810 Ultra laboratory-scale X-ray microscope equipped with a 5.4 keV rotating anode Cr source in absorption contrast and large-field-of-view (LFOV) mode. The LFOV mode covers a field of view (FOV) of 65 μm × 65 μm with a spatial resolution down to 150 nm and a pixel size of 63.89 nm. A tilt series with 40 projections in a tilt-angle range of 180° (tilt increment 4.5°) and an exposure time of 300 s per frame was acquired, as shown in SI Video 2.† We assume parallel beam geometry and a beam attenuation according to Beer–Lambert law, so that the Radon transform can be applied for reconstruction using the projection data p = −lnI/I0, where I is the measured intensity and I0 is the unattenuated incident beam intensity. The nano-CT projection images in Fig. 3 are displayed with inverted contrast. Please refer to SI Video 2† for the animated video of the original absorption contrast nano-CT tilt series.
The 360°-ET tilt series was aligned by cross correlation in FEI Inspect 3D version 3.0. The nano-CT tilt series was aligned using the adaptive motion compensation (AMC; based on Wang et al.38) procedure implemented in the native ZEISS software (XMController).
Local thickness maps39 of the pore space and, from this, corresponding pore size distributions were determined (see SI Fig. 4–9) using the FIJI local thickness plugin (FIJI40 version 2.14.0/1.54i) in the segmented reconstructed slices of the porous zeolite particle using Otsu thresholding41 in FIJI (version 2.14.0/1.54i).
6 Computational results
As an objective quality measure for the results of the simulated data set reconstructions, the relative mean error (RME) | (16) |
![[f with combining tilde]](https://www.rsc.org/images/entities/i_char_0066_0303.gif) ). Since there exist no ground truth images for the experimental data, the RME cannot be calculated there. Instead, one can calculate the raw data coverage (RDC)
). Since there exist no ground truth images for the experimental data, the RME cannot be calculated there. Instead, one can calculate the raw data coverage (RDC)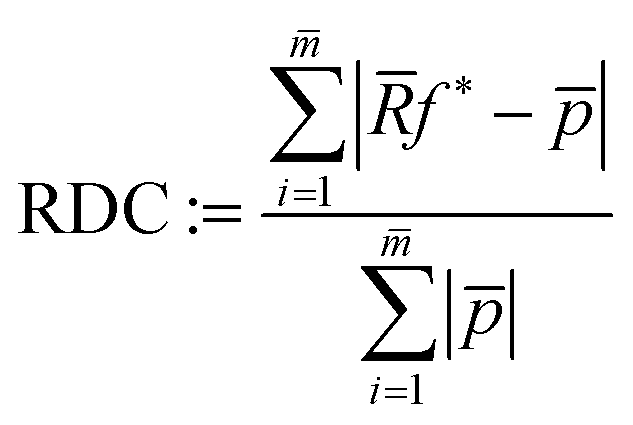 | (17) |
![[p with combining macron]](https://www.rsc.org/images/entities/i_char_0070_0304.gif) of all
of all ![[m with combining macron]](https://www.rsc.org/images/entities/i_char_006d_0304.gif) available angles.
available angles. ![[R with combining macron]](https://www.rsc.org/images/entities/i_char_0052_0304.gif) is the corresponding radon matrix. Note that the RDC is not as meaningful or reliable as the RME concerning reconstruction quality. This is due to the fact that the noise in the original projection data is not known and therefore part of the comparison. For a visual comparison, Fig. 4 shows “ground truth” images of the 2D slices that are reconstructed later in this section. Since there are no ground truths for the experimental data, the standard image reconstruction method SIRT is applied to the whole available projection data (10242 pixels each, 180 angles in Fig. 4b, 40 angles in Fig. 4c) to attain comparison images.
is the corresponding radon matrix. Note that the RDC is not as meaningful or reliable as the RME concerning reconstruction quality. This is due to the fact that the noise in the original projection data is not known and therefore part of the comparison. For a visual comparison, Fig. 4 shows “ground truth” images of the 2D slices that are reconstructed later in this section. Since there are no ground truths for the experimental data, the standard image reconstruction method SIRT is applied to the whole available projection data (10242 pixels each, 180 angles in Fig. 4b, 40 angles in Fig. 4c) to attain comparison images.
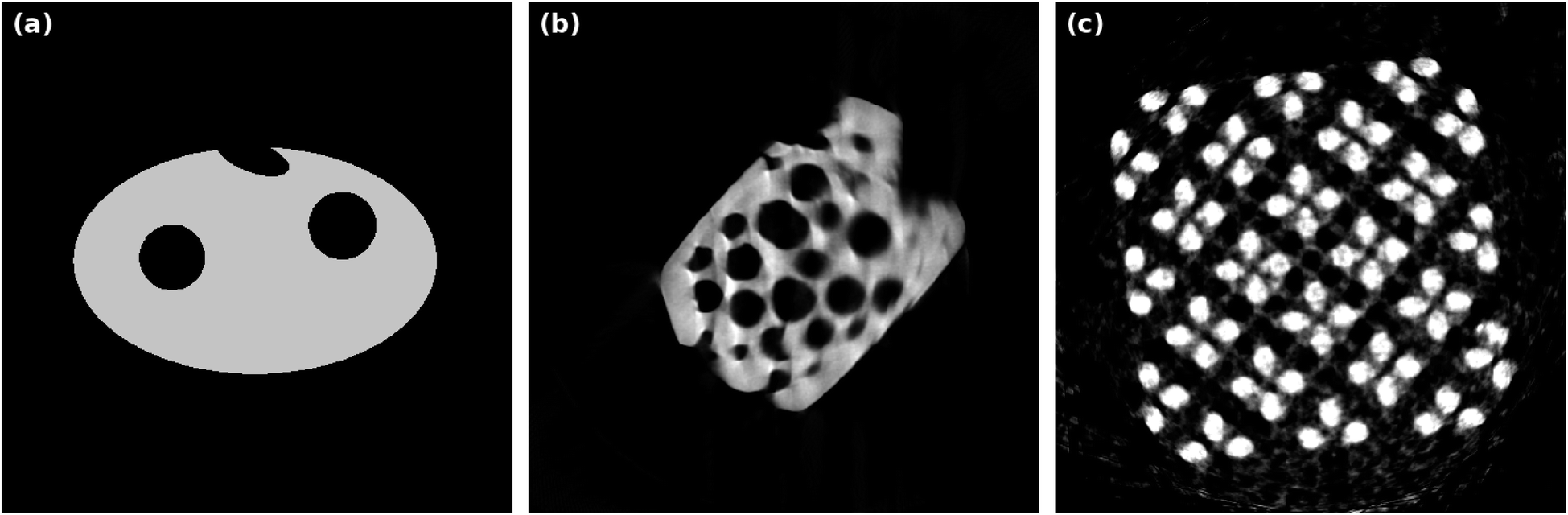 | ||
| Fig. 4 “Ground truth” images for following reconstructions: (a) simulated phantom structure, (b) SIRT reconstruction with 1000 iterations using 180 projections in a 180° tilt-angle range of a macroporous zeolite particle, (c) SIRT reconstruction with 1000 iterations using 40 projections in a 180° tilt-angle range of a copper microlattice structure. | ||
6.1 Results
As compressed sensing is designed to solve image reconstruction problems with undersampled data, meaning only a few projection angles are available or the projection range contains a missing wedge, primarily those problem settings are studied. The projection angles in the following reconstructions are always equidistantly spread over the available angular range. That is, 0° to 179° if there is no missing wedge, and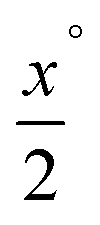 to
to 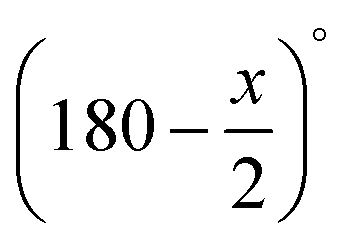 if there is a missing wedge of x°.
if there is a missing wedge of x°.
The CSHM technique is compared to the existing image reconstruction techniques CS, SIRT (with non-negativity constraints), and TVR-DART. Except for SIRT, all algorithms are specifically designed to solve problems with undersampled projection data. The evaluation is separately performed for simulated, experimental, and missing wedge projection data.
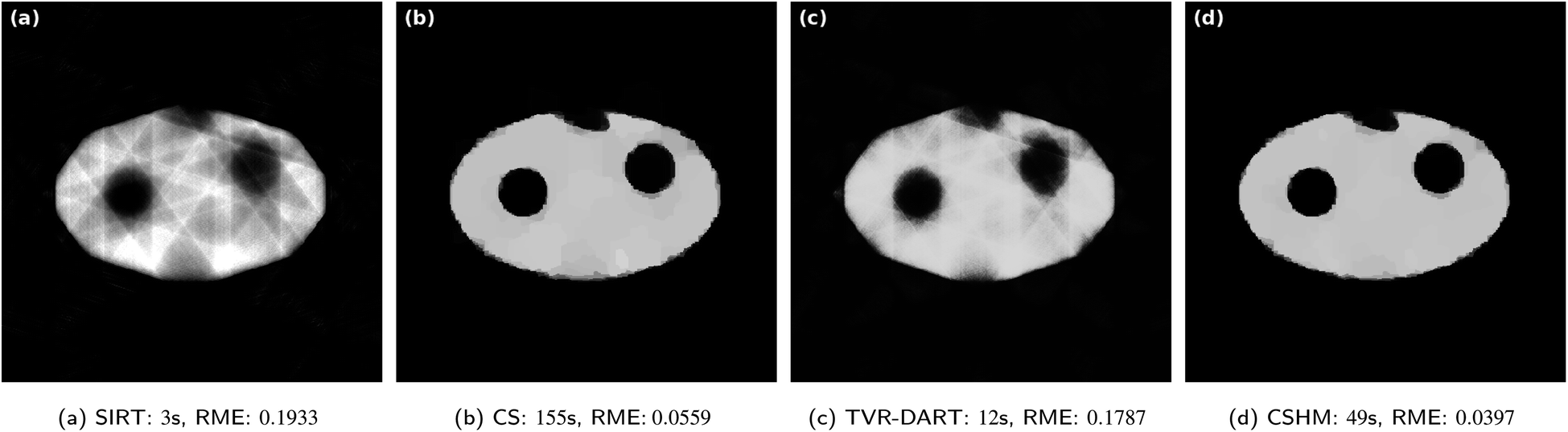 | ||
| Fig. 5 Results for simulated data with 5122 pixels, 5 projection angles, λCS = 20000 and λTVR = 500. | ||
In Fig. 6, the same reconstructions are performed with 20 projection angles. The SIRT reconstruction in Fig. 6a still contains blurry artifacts inside the sample with an RME of 0.0997. CSHM is again about three times faster than CS while producing an about 1.5 times better RME, even though visually both reconstructions look very accurate. Albeit visually comparable to the CS and CSHM reconstructions, the produced image of TVR-DART in Fig. 6c exhibits a much larger RME of 0.1166 compared to CS with 0.0281 and CSHM with 0.0184.
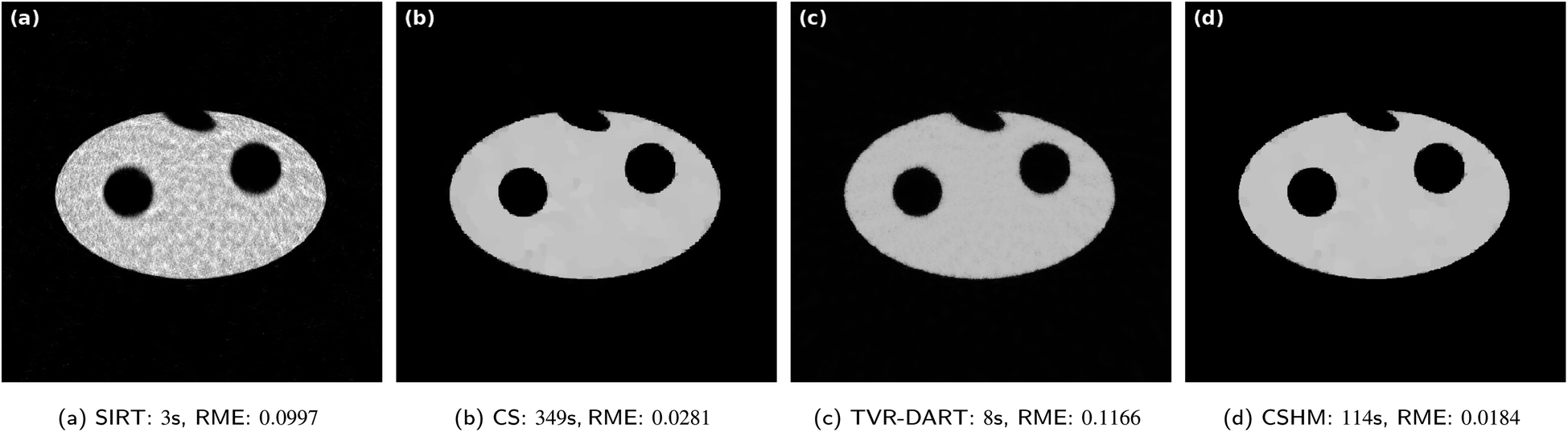 | ||
| Fig. 6 Results for simulated data with 5122 pixels, 20 projection angles, λCS = 20000 and λTVR = 500. | ||
By varying the objective function parameter λTVR in the TVR-DART problem (6), it becomes apparent that choosing a smaller parameter λTVR ∈ [10, 100], as suggested by the authors,7 the obtained RME is much lower. For example, λTVR = 10 reaches an RME of 0.0420 for the reconstruction problem of Fig. 6. However, the algorithm then does not converge in the given iteration limit, and the reconstructed image looks visually compared much worse. The empirically optimized parameter λTVR = 500 that was used in Fig. 6c aimed at producing the visually best result, not the lowest RME. A comparison of RME-optimized images and visually optimized images can be found in the ESI.† A possible explanation for this apparent contradiction can be found by looking at the solution variables. It seems a much larger penalization parameter leads to a lower material density estimation variable ρ2 (G = 2) than in a smaller penalization parameter case. This means the overall image gray values are pressed down by the penalization causing a higher RME.
To get some more insights, a comparison in RME and running time is displayed in Table 1 for a smaller pixel count of 2562 and different numbers of projection angles. The best RME of every row is displayed in bold. Here, the TVR-DART penalization parameter λTVR was chosen to produce the best RME result, not the best visual result.
000, λTVR = 10, and different amounts of projection angles. The best RME value for each number of projection angles is highlighted in bold
| Proj. angles | Running time (in seconds) | Relative mean error (RME) | ||||||
|---|---|---|---|---|---|---|---|---|
| SIRT | CS | TVR-DART | CSHM | SIRT | CS | TVR-DART | CSHM | |
| 5 | 3 | 21 | 61 | 11 | 0.1862 | 0.0522 | 0.1537 | 0.0397 |
| 10 | 3 | 30 | 8 | 15 | 0.1101 | 0.0322 | 0.0375 | 0.0233 |
| 15 | 3 | 54 | 8 | 16 | 0.0842 | 0.0264 | 0.0365 | 0.0202 |
| 20 | 3 | 59 | 4 | 21 | 0.0773 | 0.0248 | 0.0314 | 0.0178 |
| 30 | 3 | 112 | 4 | 25 | 0.0799 | 0.0234 | 0.0282 | 0.0168 |
| 45 | 3 | 276 | 7 | 52 | 0.0845 | 0.0234 | 0.0278 | 0.0159 |
| 60 | 4 | 519 | 6 | 70 | 0.0843 | 0.0241 | 0.0236 | 0.0150 |
| 90 | 4 | 931 | 6 | 207 | 0.0854 | 0.0237 | 0.0221 | 0.0148 |
| 180 | 7 | — | 13 | 1745 | 0.0746 | — | 0.0225 | 0.0141 |
SIRT solved every problem in under 10 seconds. Both CS and CSHM, which is consistently faster than CS, exhibit strictly monotonically increasing running times, which is expected for increasing problem sizes solved with an IPM. The biggest problem with 180 projection angles could not be solved anymore by CS, because the computer ran out of memory. The running times of TVR-DART are very low for all reconstructions except for the one using projections from 5 angles, indicating that the algorithm failed to converge with only 5 angles of information but managed to do so for every other number. This claim is supported by comparing the relative RME differences between 5 and 10 projection angles for all algorithms, showing by far the largest for TVR-DART.
After a monotonically decreasing RME for SIRT from 5 to 20 angles, its RME increases slightly again until it reaches its minimal RME of 0.0746 with 180 projection angles. This minimum of SIRT is bigger than the RME that all the other algorithms achieved with any number of projection angles, except TVR-DART with 5 angles. The RME of CS decreases monotonically until 45 projection angles, then slightly increases and decreases again. Its minimal RME of 0.0234 is reached with both 30 and 45 angles. The RME of TVR-DART decreases in every step except for the last one where it increases slightly. Its minimal RME of 0.0221 is marginally better than the one from CS. CSHM is able to reach a lower RME already with 15 projection angles, decreasing further in each step until a minimum of 0.0141 at 180 angles.
In all out of the nine cases, CSHM reached the lowest RME out of the four algorithms. It produced a better reconstruction with only 15 angles than any of the other algorithms did for any given number of projections while maintaining a running time ≤60 seconds for problems with 45 or fewer angles. Note that the RME of CSHM acquired with 10 projection angles is already very small. This proves the strength and high efficiency of CSHM for sparse data sets. Indeed, it yields very good and high-quality results with relatively low running times in particular in the situation when reconstructing from only a few number of projections. Having only a low number of projections at hand is a typical situation in many settings. This advantage is further fostered in the reconstructions of the following experimental data sets.
In Fig. 7, reconstructions of the experimental electron tomography projection data of the zeolite particle sample with SIRT, CS, TVR-DART and CSHM are displayed. The images contain 5122 pixels and 20 projection angles (no missing wedge) were used. Below the reconstructions, the corresponding running times and RDCs are noted. The running times are comparable to the observations from the simulated data set: SIRT is by far the fastest algorithm, followed by TVR-DART, and CSHM is considerably faster than CS. In terms of quality, the SIRT reconstruction in Fig. 7a exhibits a few artifacts outside of the sample and shows frequently alternating brightness inside the material, which should not be the case for a homogeneous sample. The reconstruction from CS in Fig. 7b has less bright-dark alternation than SIRT but a few of those artifacts can be observed here, as well. CSHM produces a visually better looking reconstruction for the zeolite in Fig. 7d. It displays almost no artifacts outside of the sample, due to the hard upper bounds, and has a nearly constant material density over the sample, due to the soft upper bounds. The shape of the pores in the CSHM reconstructions might be a little more compressed than in reality, as, e.g., the indentation on the upper left side of the particle in Fig. 7d appears a little pressed together compared to the 180 angles SIRT reconstruction in Fig. 4b. The TVR-DART reconstruction in Fig. 7c exhibits an even more homogeneous density over the whole sample than CSHM, but also a similar possible pore compression. The overall structural fidelity seems to be finer, however does not necessarily match the ground truth. For instance, very narrow pore channels appear in between several pores, which do not exist in the SIRT reconstruction with 180 projections. The corresponding raw data coverage values support the visual evaluation that the SIRT result is slightly worse than the CS result. However, the RDC of the CS result with 8.0577 is better than the RDC of 8.4071 for CSHM, despite CSHM being visually the better reconstruction. This may be owed to noise during the projection data acquisition that is reconstructed with CS but penalized and lessened by CSHM. The RDC is therefore only a rough quality measure here. The raw data coverage of 16.8910 of TVR-DART is comparatively way too large here. The same reasoning as explained for the RME in the simulated data can be applied here. An RDC of 11.3882 could be reached by TVR-DART with λTVR = 10 but the visual result is much worse than the one depicted in Fig. 7c, see the ESI† for a comparison.
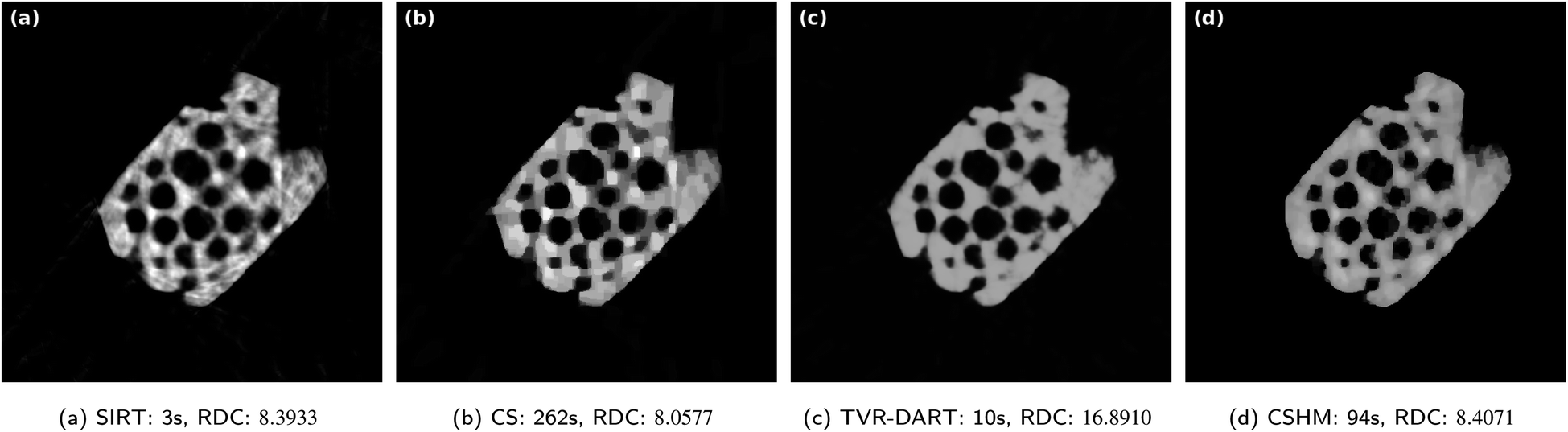 | ||
| Fig. 7 Results for experimental data set of a zeolite with 5122 pixels, 20 projection angles, λCS = 4000 and λTVR = 2000. | ||
In Fig. 8, the same zeolite reconstructions are performed with 30 projection angles. All the reconstructions improved by small amounts, the TVR-DART one a little more than the others. In a same manner, the RDC values improved for all algorithms, mostly for TVR-DART, however, its RDC of 11.8708 is still way larger than the others. Again, the raw data coverage value of the CS reconstruction is better than the one of the CSHM reconstruction, whereas visually, the one from CSHM is a more realistic image of a homogeneous sample.
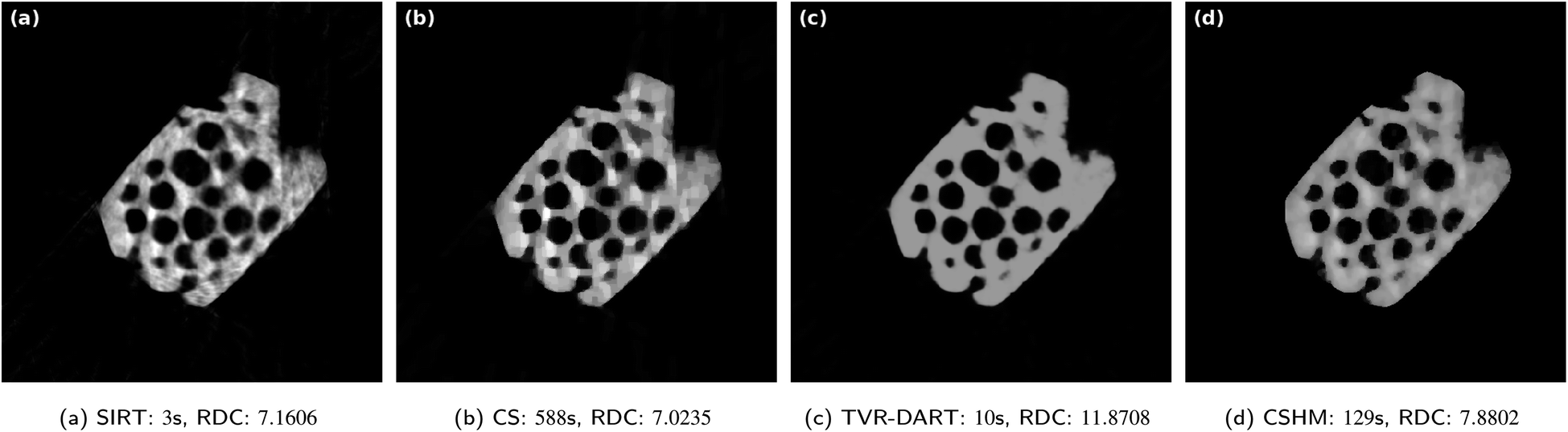 | ||
| Fig. 8 Results for experimental data set of a zeolite with 5122 pixels, 30 projection angles, λCS = 4000 and λTVR = 2000. | ||
Fig. 9 compares the different reconstructions of an exemplary slice from the copper microlattice nano-CT tilt series in absorption contrast from Fig. 3 using 40 projection angles. From a qualitative perspective, CSHM and CS provide the best and cleanest reconstructions with no streaking artifacts in the inside of the lattice structure and especially also not in the outside regions due to the hard upper bounds. The bright main copper strut features appear more homogeneous in intensity for CSHM due to the soft upper bounds, with slightly higher intensity variations in the CS slice. Although TV-DART provides the better result, both SIRT and TVR-DART reconstructions show artifacts around the outside of the specimen, and, in the sample interior, remaining streaking artifacts and stronger contrast variations are observed. Similar to the ET data set, the reconstruction fidelity of TVR-DART seems to be finer, however does not necessarily match the ground truth and is further expressed in a higher amount of noise and artifacts. Due to the increased amount of projection angles, also the running time of CS and CSHM are increased, whereas SIRT is the fastest, and also TVR-DART seems to have converged very quickly. With respect to the RDC, all four reconstructions exhibit similar values, with CSHM just showing the lowest RDC.
 | ||
| Fig. 9 Results for experimental data set of a Cu-microlattice with 5122 pixels, 40 projection angles, λCS = 3 and λTVR = 7500. | ||
Moreover, we determined local thickness maps and corresponding pore size distributions for the reconstructed slices of the porous zeolite particle (see SI Fig. 4–6 in the ESI†), which offer an alternative to judge the fidelity and precision of the different reconstruction methods. Please refer to the ESI† for the local thickness maps, the pore size distributions and an explanation and interpretation of the data.
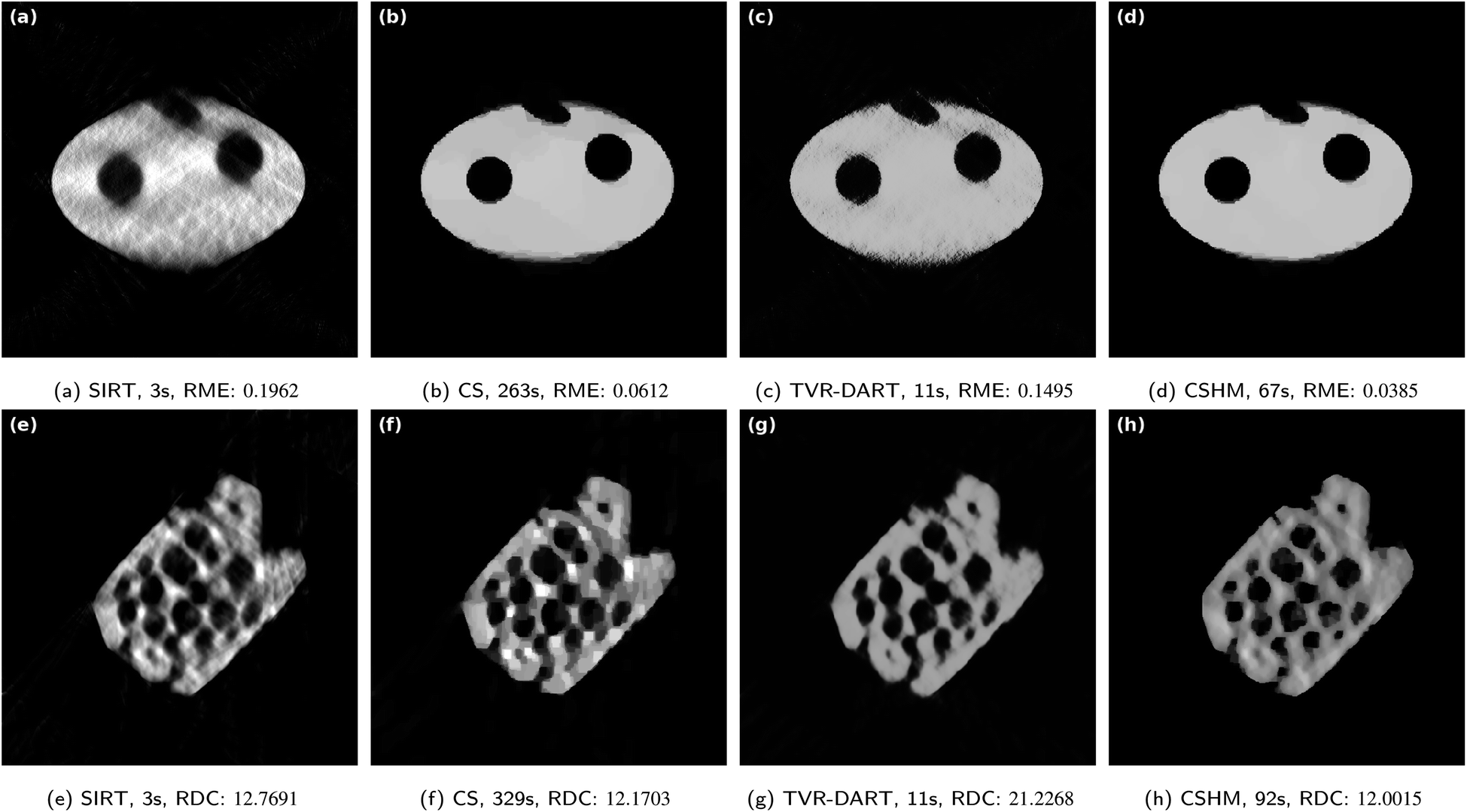 | ||
| Fig. 10 Results for a missing wedge of 60° with 5122 pixels and 11 projection angles for the simulated data set (a)–(d) and 21 projection angles for the ET data set (e)–(h). λTVR = 100 for the simulated, λTVR = 5000 for the ET data. | ||
The magnitude of the running times of the algorithms are comparable to the cases without missing wedge. CSHM outperforms the other algorithms for the simulated data set (Fig. 10a–d), both visually and regarding to the relative mean error. For the zeolite, CSHM also reaches the best RDC value, while being visually the best reconstruction. The typical elongation of reconstructions with missing wedge in vertical direction can be seen in both CSHM reconstructions of Fig. 10d and h, but the effect is relatively small when compared to the SIRT and TVR-DART reconstructions. In Fig. 10h, the pore at the lower part of the zeolite is most likely a distorted and erroneously reconstructed indentation with merged borders, which can be deduced from a comparison with the 180 angles SIRT reconstruction without missing wedge in Fig. 4b. This merging of pore walls cannot be observed in the full tilt-angle range SIRT reconstruction, nor in the missing-wedge SIRT, CS, and TVR-DART reconstructions in Fig. 10e–g. However, in those reconstructions, the missing-wedge effect causes a much stronger erroneous merging of pores (instead of pore walls), which are separate in Fig. 4b, compared to CSHM.
Similarly to the full tilt-angle range reconstructions, we determined local thickness maps and corresponding pore size distributions for the reconstructed slices with missing wedge of the porous zeolite particle (see SI Fig. 7 in the ESI†). Please refer to the ESI for the results and an explanation and interpretation of the data.
7 Conclusion
The previous section provided results obtained with the two newly developed constraints of this work. CS was combined with both hard and soft upper bounds, resulting in the here-called compressed sensing for homogeneous materials (CSHM) algorithm. CSHM was compared to SIRT, CS, and TVR-DART on simulated and experimental two-dimensional projection data from different nanotomography techniques, namely 360°-ET and nano-CT. Different problem settings were studied, including problems with a missing wedge.Regarding reconstruction quality, the results of CSHM are very convincing and of high quality. In all cases for the simulated data set, CSHM achieved the lowest relative mean error. CSHM also showed significantly decreased running times compared to CS, when solved with the same IPM. Both artifacts outside and inside of the reconstructed samples were reduced in comparison to CS, especially regarding the intensity of unexpected brighter spots inside and streaking artifacts outside of the samples. The artifacts outside of the samples were reduced by the hard upper bounds. Bounding variables to (near) 0 lets the solver eliminate a lot of variables resulting in faster solving and less required memory than without the constraint. This effect relies on a preprocessing step of subtracting the mean background noise, to have a background intensity near 0. The preprocessing step can be applied, if a mean background noise value can be estimated, e.g., if there are rays known that only pass through vacuum or air and do not hit the sample. The hard bounds are not only applicable to homogeneous samples, but to a much broader range of image reconstruction problems. They are especially efficient, when the sample is surrounded by vacuum or air. The artifacts inside the sample are reduced by the soft upper bounds, which are only applicable to homogeneous samples. They penalize larger deviations above the calculated homogeneous material density ω, leading to the density of the reconstructed sample being closer to homogeneity. A slight drawback of CSHM was shown in form of a decrease in feature sizes, e.g., pore sizes, by distributing exceeding material on the feature edges in the CSHM reconstructions. However, this effect is very small.
An advantage of CSHM compared to TVR-DART is the consistency of good solutions. From a visual perspective, TVR-DART performs very well for some instances, possibly better than CSHM. However, when applying quality measures like relative mean error or raw data coverage, CSHM reconstructions strongly outperform visually good looking TVR-DART reconstructions. Better values can be reached for TVR-DART by reducing a penalty parameter, but then in some instances TVR-DART does not converge to a solution and returns bad image reconstructions. CSHM performs consistently well, even for very few projection angles.
Missing-wedge problem reconstructions of CSHM show typical missing-wedge artifacts like elongation and the merging of features that are separate in reconstructions without missing wedge. Similar effects are observed for reconstructions of all the comparing algorithms. In comparison, CSHM exhibits the fewest merging of pores and an elongation similar to CS and better than TVR-DART.
Using more projection angles or a higher pixel count increases the running time for CSHM. Then, TVR-DART might become attractive with shorter running times, as the increment in quality of CSHM opposite TVR-DART might not be worth the large increment in running time anymore. However, as Table 1 indicates, the CSHM reconstructions do not improve by much anymore for an increasing number of projection angles, compared to a reconstruction with only a few angles, which is already very accurate.
This justifies reconstructing images with only a few projection angles, keeping the running time within an acceptable range. When reconstructing with only very little information (very few projection angles), CSHM outperforms TVR-DART in quality, as TVR-DART does not converge to a good reconstruction. Then, CSHM represents the most efficient choice for image reconstruction. To decrease high running times, existing work can be applied to the used IPM. Multiple approaches were proposed in the literature, e.g., using a matrix-free IPM to speed up the search step of the Newton method, developed by Fountoulakis et al.,42 or accelerating the IPM by performing parallel computations on the GPU, where promising results were obtained by Lee et al.43
In conclusion, CSHM represents a competitive alternative to existing algorithms for smaller and medium-sized image reconstruction problems of homogeneous samples. It provides high quality results for highly undersampled data in nanotomography, including missing-wedge problems. Non-homogeneous sample reconstructions can still benefit from the hard upper bounds that reduce artifacts around the studied objects. Furthermore, an extension of the soft upper bounds to a version that can handle samples composed of few, but more than one, density values is thinkable. This is a question for future work.
Data availability
The tilt series raw data and the Python scripts of the implemented algorithms are publicly available on Zenodo https://doi.org/10.5281/zenodo.10283560.Author contributions
Sebastian Kreuz: methodology, software, investigation, writing – original draft. Benjamin Apeleo Zubiri: conceptualization, methodology, validation, writing – review & editing. Silvan Englisch: validation, data curation. Sung-Gyu Kang: writing – review & editing. Moritz Buwen: validation, data curation. Rajaprakash Ramachandramoorthy: writing – review & editing. Erdmann Spiecker: writing – review & editing. Frauke Liers: conceptualization, methodology, writing – review & editing. and Jan Rolfes: conceptualization, methodology, writing – review & editing.Conflicts of interest
There are no conflicts to declare.Acknowledgements
We acknowledge funding by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) - Project-ID 416229255 - SFB 1411. We thank Alexander Götz for the help with the acquisition of the nano-CT data set.References
- B. Apeleo Zubiri, J. Wirth, D. Drobek, S. Englisch, T. Przybilla, T. Weissenberger, W. Schwieger and E. Spiecker, Adv. Mater. Interfaces, 2021, 8, 2001154 CrossRef CAS.
- P. J. Withers, C. Bouman, S. Carmignato, V. Cnudde, D. Grimaldi, C. K. Hagen, E. Maire, M. Manley, A. Du Plessis and S. R. Stock, Nat. Rev. Methods Primers, 2021, 1, 18 CrossRef CAS.
- T. Burnett, S. McDonald, A. Gholinia, R. Geurts, M. Janus, T. Slater, S. Haigh, C. Ornek, F. Almuaili and D. Engelberg, et al. , Sci. Rep., 2014, 4, 4711 CrossRef CAS PubMed.
- W. Van den Broek, A. Rosenauer, B. Goris, G. Martinez, S. Bals, S. Van Aert and D. Van Dyck, Ultramicroscopy, 2012, 116, 8–12 CrossRef CAS.
- R. T. White, D. Ramani, S. Eberhardt, M. Najm, F. P. Orfino, M. Dutta and E. Kjeang, J. Electrochem. Soc., 2019, 166, F914 CrossRef CAS.
- S. Takeya, S. Muromachi, A. Hachikubo, R. Ohmura, K. Hyodo and A. Yoneyama, Phys. Chem. Chem. Phys., 2020, 22, 27658–27665 RSC.
- X. Zhuge, W. J. Palenstijn and K. J. Batenburg, IEEE Trans. Image Process., 2015, 25, 455–468 Search PubMed.
- M. Slaney and A. Kak, Principles of Computerized Tomographic Imaging, IEEE press, 1988 Search PubMed.
- P. Gilbert, J. Theor. Biol., 1972, 36, 105–117 CrossRef CAS PubMed.
- A. C. Kak and M. Slaney, Principles of Computerized Tomographic Imaging, SIAM, 2001 Search PubMed.
- E. J. Candès, J. K. Romberg and T. Tao, Commun. pure appl. math., 2006, 59, 1207–1223 CrossRef.
- S. Qaisar, R. M. Bilal, W. Iqbal, M. Naureen and S. Lee, J. Commn. Net., 2013, 15, 443–456 Search PubMed.
- Y. Xi, Z. Qiao, W. Wang and L. Niu, Optik, 2020, 204, 163814 CrossRef.
- M. Lustig, D. Donoho and J. M. Pauly, Magn. Reson. Med., 2007, 58, 1182–1195 CrossRef PubMed.
- F. Knoll, K. Bredies, T. Pock and R. Stollberger, Magn. Reson. Med., 2011, 65, 480–491 CrossRef PubMed.
- R. Leary, Z. Saghi, P. A. Midgley and D. J. Holland, Ultramicroscopy, 2013, 131, 70–91 CrossRef CAS PubMed.
- P. Hartel, H. Rose and C. Dinges, Ultramicroscopy, 1996, 63, 93–114 CrossRef CAS.
- S. S. Chen, D. L. Donoho and M. A. Saunders, J. Soc. Ind. Appl. Math., 2001, 43, 129–159 Search PubMed.
- S. Foucart and H. Rauhut, A Mathematical Introduction to Compressive Sensing, Springer, 2012, p. 58 Search PubMed.
- S. Foucart and H. Rauhut, A Mathematical Introduction to Compressive Sensing, Birkhaeuser, New York, 2013, pp. 56–57 Search PubMed.
- K. T. Block, M. Uecker and J. Frahm, Magn. Reson. Med., 2007, 57, 1086–1098 CrossRef PubMed.
- J. Wirth, S. Englisch, D. Drobek, B. Apeleo Zubiri, M. Wu, N. Taccardi, N. Raman, P. Wasserscheid and E. Spiecker, Catalysts, 2021, 11, 810 CrossRef CAS.
- T. Johnson, J. Bailey, F. Iacoviello, J. Welsh, P. Levison, P. Shearing and D. Bracewell, J. Chromatogr. A, 2018, 1566, 79–88 CrossRef CAS PubMed.
- S. V. Venkatesan, M. El Hannach, S. Holdcroft and E. Kjeang, J. Membr. Sci., 2017, 539, 138–143 CrossRef CAS.
- P. Trogadas, O. O. Taiwo, B. Tjaden, T. P. Neville, S. Yun, J. Parrondo, V. Ramani, M.-O. Coppens, D. J. Brett and P. R. Shearing, Electrochem. Commun., 2014, 48, 155–159 CrossRef CAS.
- F. Liers and G. Pardella, Discrete Appl. Math., 2011, 159, 2187–2203 CrossRef.
- E. Y. Sidky and X. Pan, Phys. Med. Biol., 2008, 53, 4777–4807 CrossRef PubMed.
- S.-J. Kim, K. Koh, M. Lustig, S. Boyd and D. Gorinevsky, IEEE J. Sel. Top. Signal Process., 2007, 1, 606–617 Search PubMed.
- W. Van Aarle, W. J. Palenstijn, J. De Beenhouwer, T. Altantzis, S. Bals, K. J. Batenburg and J. Sijbers, Ultramicroscopy, 2015, 157, 35–47 CrossRef CAS PubMed.
- Gurobi Optimization, LLC, Gurobi Optimizer Reference Manual, 2023, https://www.gurobi.com Search PubMed.
- Y. Jin and B. D. Rao, 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, 2010, pp. 3830–3833 Search PubMed.
- S. V. Venkatakrishnan, L. F. Drummy, M. A. Jackson, M. De Graef, J. Simmons and C. A. Bouman, IEEE Trans. Image Process., 2013, 22, 4532–4544 CAS.
- S. Venkatakrishnan, L. F. Drummy, M. Jackson, M. De Graef, J. Simmons and C. A. Bouman, IEEE Trans. Comput. Imaging, 2014, 1, 1–15 Search PubMed.
- A. G. Machoke, A. M. Beltrán, A. Inayat, B. Winter, T. Weissenberger, N. Kruse, R. Güttel, E. Spiecker and W. Schwieger, Adv. Mater., 2015, 27, 1066–1070 CrossRef CAS PubMed.
- T. Przybilla, B. A. Zubiri, A. M. Beltrán, B. Butz, A. G. Machoke, A. Inayat, M. Distaso, W. Peukert, W. Schwieger and E. Spiecker, Small Methods, 2018, 2, 1700276 CrossRef.
- S.-G. Kang, B. Bellon, L. Bhaskar, S. Zhang, A. Gotz, J. Wirth, B. Apeleo Zubiri, S. Kalacska, M. Jain, A. Sharmaet al., arXiv, 2023, Preprint, arXiv:2311.14018, DOI:10.48550/arXiv.2311.14018.
- R. Ramachandramoorthy, S. Kalácska, G. Poras, J. Schwiedrzik, T. E. Edwards, X. Maeder, T. Merle, G. Ercolano, W. W. Koelmans and J. Michler, Appl. Mater. Today, 2022, 27, 101415 CrossRef.
- J. Wang, Y.-c. K. Chen, Q. Yuan, A. Tkachuk, C. Erdonmez, B. Hornberger and M. Feser, Appl. Phys. Lett., 2012, 100, 143107 CrossRef.
- T. Hildebrand and P. Rüegsegger, J. Microsc., 1997, 185, 67–75 CrossRef.
- J. Schindelin, I. Arganda-Carreras, E. Frise, V. Kaynig, M. Longair, T. Pietzsch, S. Preibisch, C. Rueden, S. Saalfeld and B. Schmid, et al. , Nat. Methods, 2012, 9, 676–682 CrossRef CAS PubMed.
- N. Otsu, IEEE Trans. Syst. Man. Cybern., 1979, 9, 62–66 Search PubMed.
- K. Fountoulakis, J. Gondzio and P. Zhlobich, Math. Program. Comput., 2014, 6, 1–31 CrossRef.
- S. Lee, H. Lee, Y. Kim, J. Kim and W. Choi, Sensors, 2022, 22, 4512 CrossRef PubMed.
Footnote |
| † Electronic supplementary information (ESI) available. See DOI: https://doi.org/10.1039/d3na01089a |
| This journal is © The Royal Society of Chemistry 2024 |