
 Open Access Article
Open Access Article This Open Access Article is licensed under a Creative Commons Attribution-Non Commercial 3.0 Unported Licence
This Open Access Article is licensed under a Creative Commons Attribution-Non Commercial 3.0 Unported LicenceWater discrimination based on the kinetic variations of AgNP spectrum†
Masoud Shariati-Rad *ab and
Yalda Mozaffaria
*ab and
Yalda Mozaffaria
aDepartment of Analytical Chemistry, Faculty of Chemistry, Razi University, Kermanshah, Iran. E-mail: mshariati_rad@yahoo.com; Fax: +98 833 4274559
bResearch Group of Design and Fabrication of Kit, Razi University, Kermanshah, Iran
First published on 17th September 2020
Abstract
The assessment of water quality and its classification have considerable importance on public health. This requires monitoring of a wide range of physical, chemical and biological parameters. Here, an array of sensors composed of absorbances in different wavelengths in a kinetic process was used for classification. The data were obtained in the kinetic absorbance variations of silver nanoparticles (AgNPs) in the presence of different mineral waters. Spectral variations with time for each water sample were vectorized, and the matrix composed of these vectors was analyzed using principal component analysis (PCA) and hierarchical cluster analysis (HCA) as unsupervised clustering methods. The distinct clusters of nine different water samples were obtained using PCA and clustering by HCA resulted in an error rate of only 14.8%, which corresponds to misclassification of 4 water samples out of 27. The ability of the method for the discrimination of water samples using AgNP as the sole reagent can be attributed to the high dimensionality of data and the influence of the chemical environment in each water sample on the absorbance variations of AgNPs.
1. Introduction
In the water industry, the discrimination of a large number of different mineral waters is necessary. Moreover, counterfeit mineral waters should be distinguished because of the influence on human health. Marketing the mineral waters without any license is one of the cases that may occur. Therefore, distinguishing between different waters and the elucidation of adulteration is very important. Water from different areas has different components because of different geochemical environments. A mineral water obtained from a given spring has unique properties, which can be used to differentiate between different waters.The differentiating of different water samples has been performed using electrochemical methods.1–8 The basis for these methods is the analysis of waters for different ion species. For these cases, the strategy for differentiating relies on using an array of sensors (electrodes) that are non-specific, which are selective for chemical species but can differently respond to a group of related chemical species.9 In electronic tongues or noses, different electrodes of different types10–15 are employed. The preparation of thick film potentiometric electrodes has been used in the discrimination of water types.16 Though electronic tongues using the potentiometric methods are based on simply measuring the potential between two electrodes, the preparation of several electrodes is expensive.
In another approach, species in the water samples can be determined by methods other than electrochemistry and used to cluster water samples. These include ICP-MS, atomic absorption spectrometry and spectrophotometry.17–23 Due to the large number of determinations required, the expense of analyses is extremely high and the time required for analyses increases.
There are limited published studies that report on the use of optical phenomenon such as spectrofluorimetry24,25 in the design of sensor arrays in water differentiation. As reported in ref. 24 and 25, sensor arrays are composed of different chemical reagents to differentiate waters. Therefore, the expense of the analyses by these arrays increases. However, the literature review shows that the use of spectrophotometric data in water clustering is rare.
In the literature works, a large number of water properties are measured and used to differentiate waters. Clearly, this procedure requires a number of measurements and reagents. In this work, nine different commercial mineral waters were explained using the sensor array composed of absorbance changes. Silver nanoparticles can be prepared by simple procedures. Owing to unique optical sensing properties of noble metal nanoparticles such as AgNPs, they have reported widespread use in almost every field of chemistry, particularly in analytical chemistry. AgNPs have high extinction coefficients and low cost and remain dispersed in the solution.
Silver nanoparticles (AgNPs) as the sole reagent were employed to differentiate waters. AgNPs have been used to discriminate amino acids26 and detect biothiols.27 As per these published works, AgNPs should be functionalized to enhance their selectivity.
Usually, the experimental data of sensor arrays arranged in vectors can be analyzed by chemometric methods such as principal component analysis (PCA) and hierarchical cluster analysis (HCA),28 which are unsupervised clustering methods.
2. Principal component analysis and hierarchical cluster analysis
For unsupervised classification, PCA and HCA are usually used to analyze data. Cluster analysis is a well-established approach that was primarily developed by biologists to determine similarities between organisms.HCA is based on the grouping of sample vectors as per their spatial distances in their full vector space. The first step is to determine similarity between objects, and the next step is to link objects whereby single objects are gradually connected to each other in groups. The primary purpose of HCA is to divide analytes into discrete groups based on characteristics of their respective responses.
PCA is one of the several multivariate methods that allow us to explore patterns in data taken from sensor arrays. In PCA, variables in the data matrix of the sensor array are mathematically transformed to extract new abstract variables called scores with reduced redundancy in dimensionality. PCA makes it possible to extract useful information from original data.
3. Experimental
3.1. Instrumentation and software
All absorbances, including the kinetic spectra of AgNP in the presence of different waters, were recorded using an Agilent 8453 UV-Vis spectrophotometer with a diode array detector equipped with 1 cm path-length quartz cells.A transmission electron micrograph (TEM) of the synthesized AgNP was recorded using a Zeiss EM900 transmission electron microscope.
The PCA toolbox for MATLAB was used for PCA and the unsupervised exploration of kinetic spectrophotometric data.29
3.2. Chemicals
Ammonia (25% concentrated solution), ethanol (99.5%) and silver nitrate (99.0%) were purchased from Merck (Darmstadt, Germany).3.3. Synthesis of AgNP
For the reduction of Ag+ to produce corresponding AgNP, carbon dots (CDs) were used. Firstly, CDs were synthesized by simply heating apple juice using the hydrothermal method.30–33 Briefly, the apple was cut and crushed in 100 mL of water and filtered. Then, after adding 20 mL of ethanol to 20 mL of the filtrate, the mixture was heated at a constant temperature of 150 °C for 4 h in an autoclave. After that, the dark brown reaction mixture was cooled to room temperature. For obtaining the CD solution, the abovementioned mixture was centrifuged for 2 min (3000 rpm), and the homogeneous supernatant was used for synthesizing AgNPs. In the next step, CD was used as the reductant of AgNO3 to produce AgNPs.31,32Briefly, 100 μL of the solution of the synthesized CD with a concentration of 50 mg mL−1 was added to 100 mL of boiling deionized water. After boiling the mixture for 15 min, 1 mL of ammonia solution (10%, w/w) and fresh AgNO3 solution (5 mL, 20 mM) were sequentially added with stirring for 2 min. This reaction was continued for 50 min at 90 °C. Finally, the yellow solution of AgNPs was produced (Fig. 1).
 | ||
| Fig. 1 Image of synthesized yellow AgNP. | ||
3.4. TEM microscopy
Fig. S1† shows the transmission electron micrograph of the synthesized AgNP. Estimation based on the micrograph showed that the average size of the prepared AgNP is 7.8 ± 2.4 nm. The solution of the synthesized AgNP is yellow in color and stable.3.5. Water samples
A series of nine natural bottled mineral waters were selected for the examination of the method applied for their discrimination. Table 1 lists the names of water samples.| Class | Name |
|---|---|
| 1 | Azmar |
| 2 | Bisheh |
| 3 | Damavand |
| 4 | Dasany |
| 5 | Kimia |
| 6 | Pure life |
| 7 | Rijab |
| 8 | Souver |
| 9 | Vatta |
3.6. Kinetic spectrophotometric measurements
In this study, strategy based on the kinetic changes of the spectrum of AgNPs in the presence of different waters was used to cluster waters. For this purpose, to 1.0 mL of synthesized AgNP, 1.0 mL of water sample was added and the corresponding kinetic spectra were recorded in the wavelength range of 320–800 nm. The kinetic spectra were recorded for 0.0–7.0 min in time intervals of 20 s in the first 4 min; then, it was recorded in time intervals of 30 s. It must be mentioned that, for each sample, three replicate kinetic spectrophotometric measurements were made.4. Results and discussion
4.1. UV-vis spectrum of the synthesized AgNP
Fig. S2† shows the absorption spectrum of the synthesized AgNP. The synthesized AgNP possess a single main absorbance maximum located at 420 nm. In the presence of real water samples, time-dependent absorbance changes were observed.4.2. Statistical analysis
For each water sample, three replicate kinetic spectrophotometric measurements were performed. However, for comparison purposes, some of them have been shown in Fig. 2. For all samples, a decrease in absorbance at the main peak (420 nm) is observed; at the high wavelength region (∼720 nm), an increased absorption is observed with time. As a point for seeking differences, differences in the location and the intensity of the maxima of the absorption spectra can be mentioned. However, based on the amount of absorbances, it is not possible to elucidate the water samples. For water sample named Souvere, class 8 (Fig. 2f), in contrast to the other water samples, increased absorption is observed with time for wavelengths of higher than 500 nm. It can be deduced by following the color of the spectra with time. However, such differences cannot be observed for all of the water samples that were examined. Therefore, from the visual inspection of the kinetic spectra of water samples, it is hard or impossible to differentiate water samples.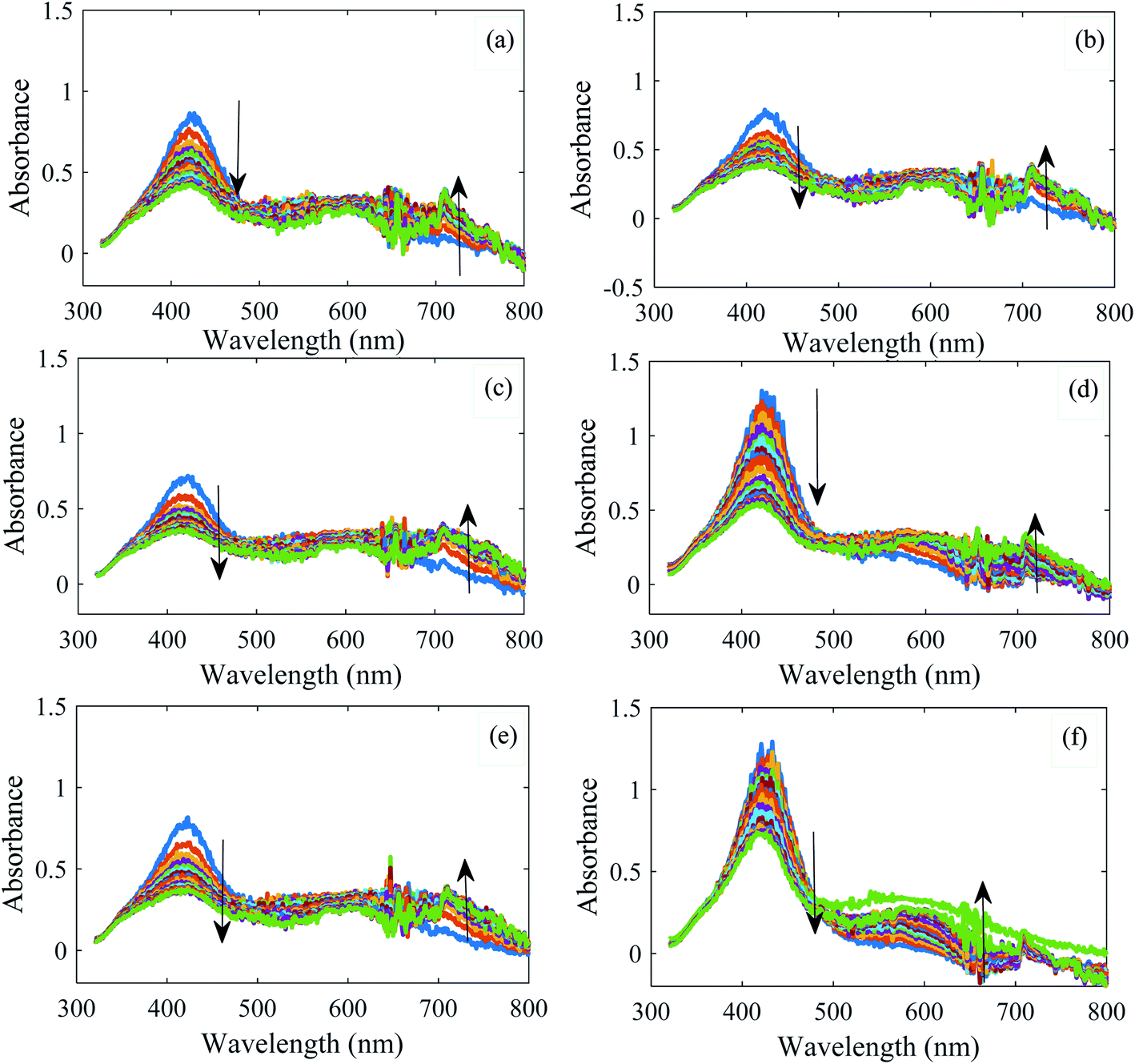 | ||
| Fig. 2 Absorbance changes of AgNPs in the presence of different water samples: (a) Bisheh, (b) Damavand, (c) Kimia, (d) Pure life, (e) Rijab and (f) Souvere. Conditions: total volume = 2.0 mL, volume of AgNP = 1.0 mL and volume of real water = 1.0 mL, time = 0.0–7.0 min. Arrows show the direction of absorbance changes. | ||
Each kinetic data was recorded 19 times (0.0–7.0 min) in the wavelength range of 320–800 nm. Therefore, a data matrix of dimension 19 × 481 was obtained for each water sample.
In PCA,34,35 information of a large number of variables can be abstracted into a small number of new orthogonal variables called principal components (PCs) using linear combination. Variance explained by calculated PCs decreases from PC1 to the other ones. Using PCA, it is possible to examine the patterns of samples with a large number of variables.
As an initial strategy for clustering, for accounting the kinetic behavior of AgNP in the presence of different water samples to differentiate water samples, kinetic changes in the maximum absorption wavelength of AgNP at 420 nm for each water sample was followed. Therefore, for each water sample, a vector of absorbance with time was obtained. Eventually, a matrix with dimension 27 × 19 was resulted. The processing of kinetic data by PCA resulted in scores (shown in Fig. 3), of which two first PCs accounted for 99.91% of total variance. Clearly, true clustering of samples was not observed. However, in certain samples (classes 6, 8, 1 and 5), clustering to some extent can be observed. For other water samples, clusters with certain overlap are observed. Overlap between classes (4 and 9), (2 and 3) and (3 and 7) can be clearly seen.
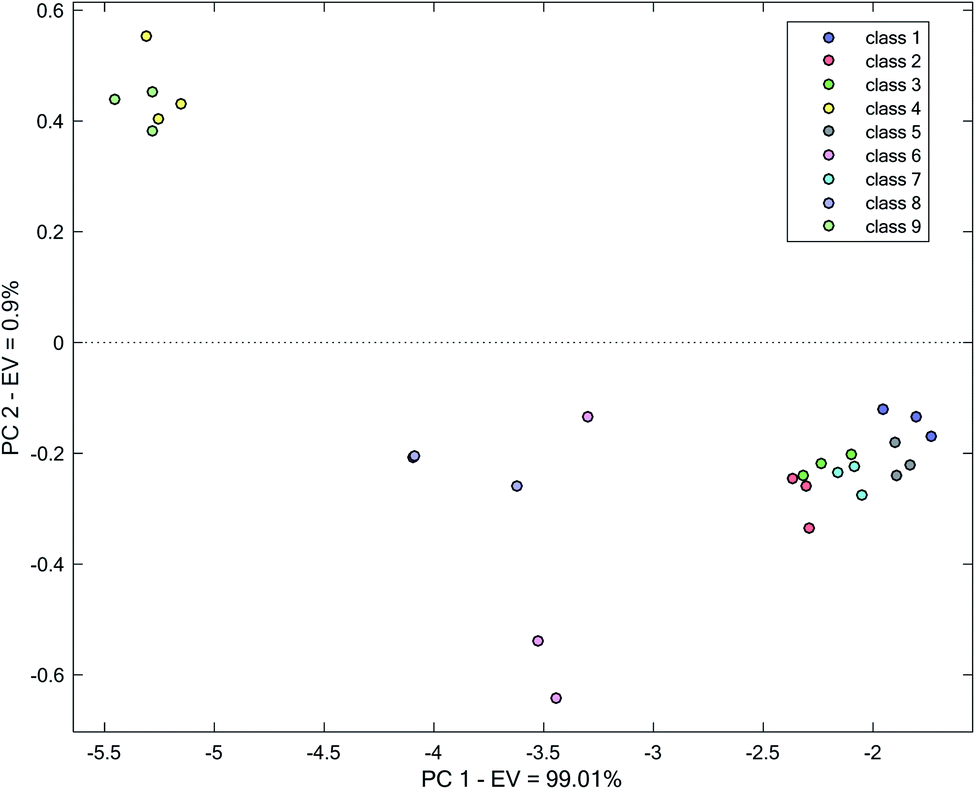 | ||
| Fig. 3 Score plot obtained by the application of PCA on the kinetic spectrophotometric data at 420 nm. | ||
In Fig. S3,† a corresponding loading plot has been demonstrated. From the loading plot, it can be possible to realize the importance of variables used in PCA. This can be performed by inspecting the magnitude of variables. As can be seen in Fig. S3,† the magnitude of loading for variables (times) on the first PC reduces with time. On the second PC, it is reduced to variable 8 (time 8) and then increased. However, based on percent variation explained by two PCs, it can be reliable to speak about the significance of the variables using only PC1. Therefore, it can be concluded that the initial and the terminal variables (times) are the most important variables that differentiate water samples.
In the next step, variation in the absorbance of water samples in a broader range, including wavelengths of 410–430 nm, was examined for clustering. Data matrix for each water sample was vectorized and used for PCA. The result of PCA applications on the obtained matrix has been shown in Fig. 4. Improvement in the clustering relative to Fig. 3 is observed. It can clearly be observed that a good improvement in the separation of different water has occurred. In multiple cases, distinct boundaries between different water samples can be drawn. As can be seen, a more distinct differentiation of classes 2, 3 and 7 occurs compared to the previous clustering with only information in 420 nm (Fig. 3).
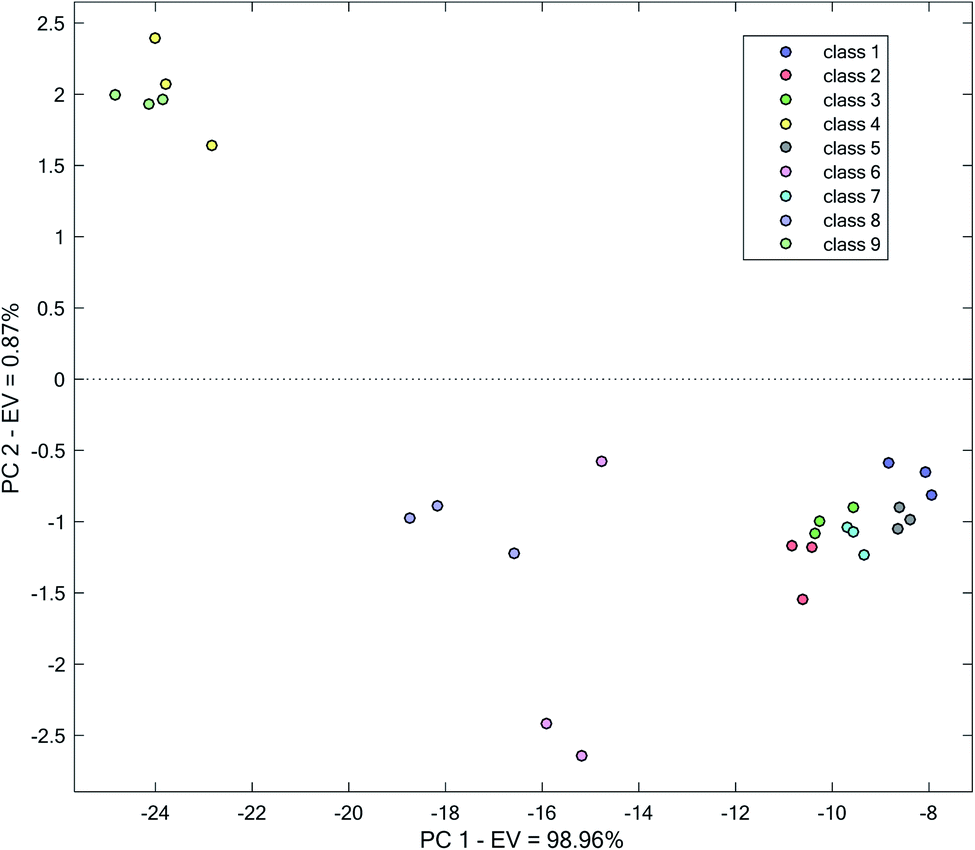 | ||
| Fig. 4 Score plot obtained by the application of PCA on the kinetic spectrophotometric data in the range of 410–430 nm. | ||
However, to certain extent, overlapping of clusters of classes 3 and 7 and 9 and 4 can be seen. Though it can be possible to distinguish different water samples, separation between them is low. Relative to the use of the single wavelength of 420 nm for the analysis, improvements in the separation of all different water samples is observed, especially for classes (4 and 9), (2 and 3) and (3 and 7).
To use PCA and eventually obtain scores for each sample, the third strategy based on vectorizing the complete kinetic matrices was selected. In these conditions, each water sample can be characterized with a vector with dimension 1 × (19 × 481). Combining these vectors for water samples, a matrix of dimension 27 × (15 × 380) is obtained.
In Fig. 5, a score plot based on the two first PCs after applying PCA on the complete data has been shown. The two first PCs accounted for 84.85% and 13.55% of total variance, respectively, i.e., 98.4% of total variation in data. Therefore, an examination of these PCs can be sufficient to visualize data.
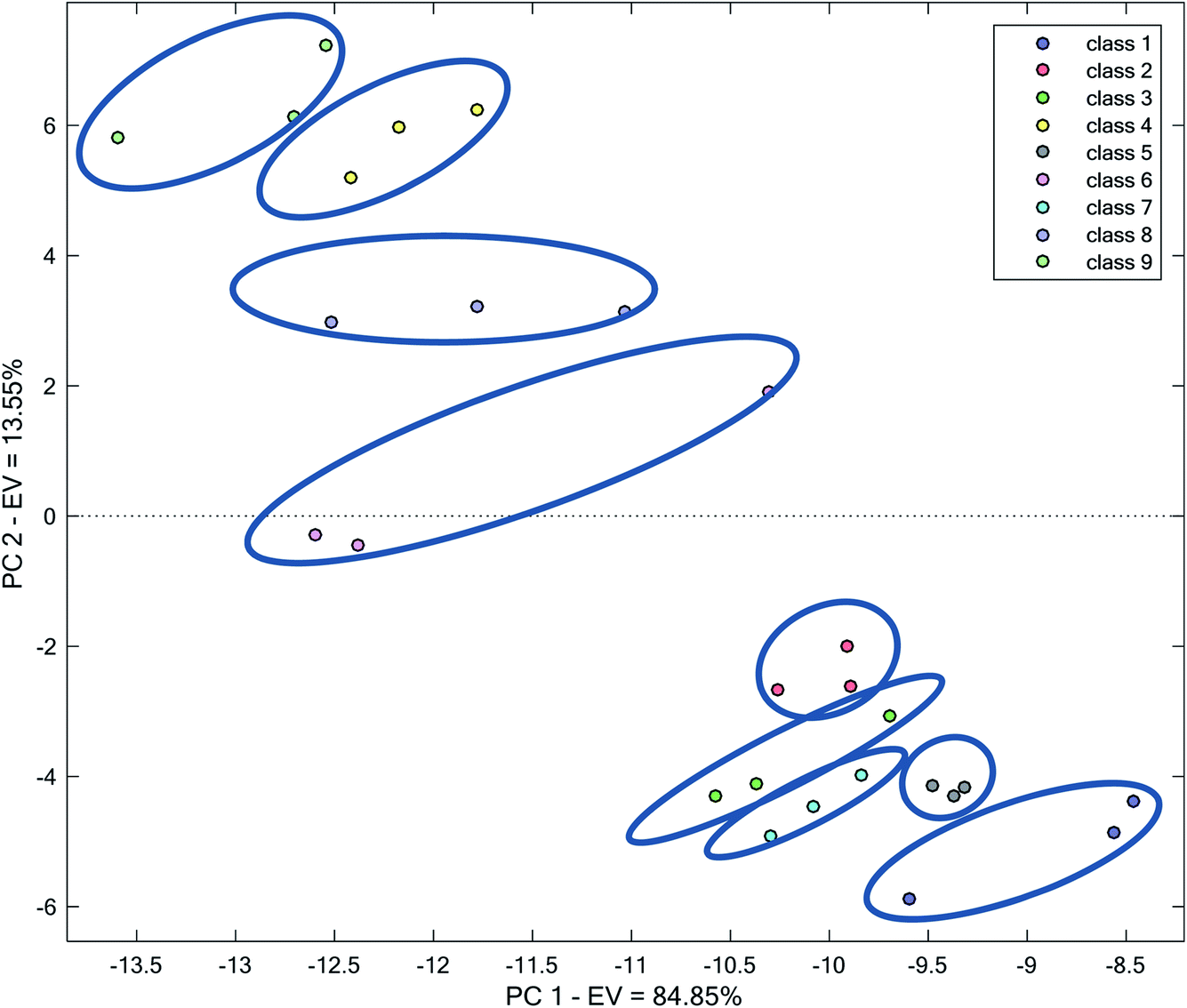 | ||
| Fig. 5 Score plot obtained by the application of PCA on the complete kinetic spectrophotometric data. | ||
Fig. 5 shows that all of the analyzed water samples form distinct and clear clusters. However, the area covered by each water sample in Fig. 5 is different. For example, classes 1, 6, 8 and 9 extend to a broad space in the plot, whereas the replicates related to classes 2, 5 and 7 are closer to each other. This amount of the dispersion of replicates can be related to between measurement errors, which are primarily randomized. Therefore, the clustering pattern is systematic and the method for clustering is reliable. This indicates that the complete kinetic spectrophotometric data of AgNPs in the presence of different water samples can be utilized for classification purposes. The success in clustering in this strategy can be related to using a higher number of variables, which provided us with higher advantages because of multivariate data and using higher spectral features and characteristics of the mixture of AgNP + water sample, which may differ from one water sample to another. Overall, the waters in Fig. 5 can be considered as two main clusters: with positive (classes 4, 6, 8, and 9) or negative (classes 1, 2, 3, 5, and 7) scores on PC2.
The location of different water samples in the space of the score plot reflects the different responses of AgNPs to different water samples. In the examined waters and pH of each water, this different response originates from differences in the nature and the concentration of various species. Nevertheless, the relative locations of the water samples in the score plot roughly reflect the differences in their quality.
HCA, as another clustering method, which uses high dimensional data, was employed for differentiating analyzed water samples.36 In HCA, distances between the vectors of different waters in the complete space of the data is used to classify samples.
There exist various related methods for defining clusters from the set of analyte vectors. In this case, data were first mean-centered and HCA was performed using complete linkage of samples and city block as distance measure. These clusters were then grouped together to form new larger clusters. The operation was repeatedly performed until only a single big cluster remains. The analysis of the data by HCA results in a dendrogram, which elucidates similarities between various water samples. Quantitatively, the dendrogram shows the amount of the similarity of the responses in the matrix was analyzed. Moreover, it can be used to identify the closest group that an unknown sample belongs to. In Fig. 6, a dendrogram obtained by the application of HCA on the complete kinetic spectrophotometric data has been demonstrated.
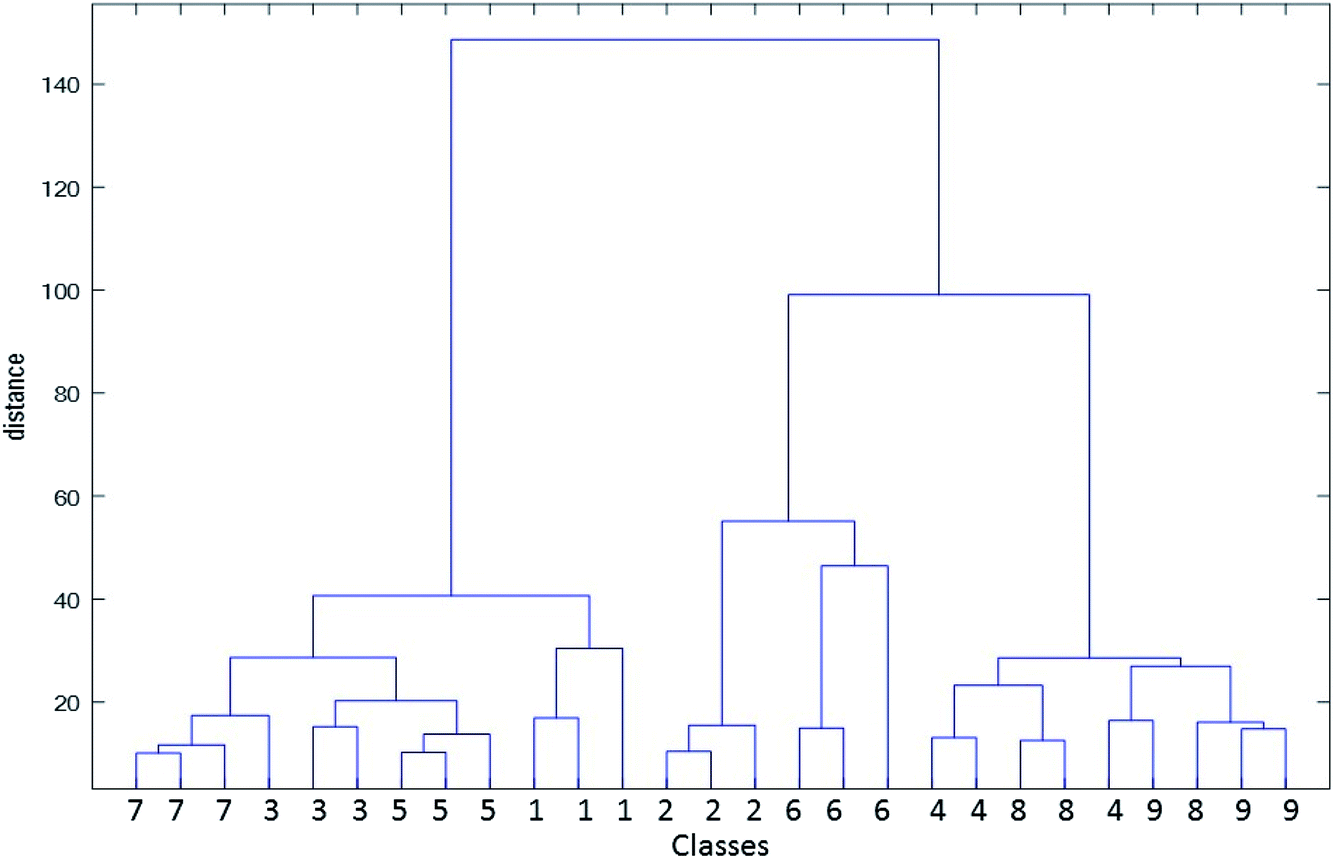 | ||
| Fig. 6 Dendrogram obtained by the application of HCA on the complete kinetic spectrophotometric data of analyzed water samples. | ||
When examining Fig. 6, it can be seen that most water samples have been grouped in true clusters; however, samples 9, 11, 23 and 25 have been incorrectly clustered. Therefore, error rate in the classification by HCA as an unsupervised clustering method is 14.8% (number of the incorrectly classified sample to the all of the analyzed samples), which is acceptable. Furthermore, similarity between classes can be inferred from the dendrogram. For example, samples 4, 5 and 6 (class 2) as well as 16, 17 and 18 (class 6) contribute to the construction of a larger group. These two samples are close to each other in Fig. 5. For classes 1 (samples 1, 2 and 3) and 5 (samples 13, 14 and 15), this can be mentioned. Two main groups elucidated in the score plot of PCA can be seen in the dendrogram.
Although it seems that a limited type of sensor (absorbance) is used and the discrimination may not be possible, the results showed that clustering is successful. This can be related to the effect of the matrix of water samples on the absorbance data and its changes. As is known, the matrix of a sample is composed of all the species, including different cations, anions and other molecular species present in the sample. In our previous published work,37 a similar phenomenon was used to discriminate natural water based on the color changes of carbon dots in the presence of examined waters.
5. Conclusions
A method was introduced for water clustering without using any parameter or characteristics of water samples. Kinetic absorption data in the reaction of different waters with AgNPs was used as a straightforward method for the clustering of mineral water samples. Water samples were then successfully clustered using PCA and HCA. The method can be used for assessing the water quality based on its comparison with a reference water using the method introduced in this research. Rather than using a large number of parameters or characteristics or even multiple reagents conventionally employed in sensor arrays, a single reagent (AgNP) is introduced.Ethical approval
Ethical approval was not required for the work presented in this study.Informed consent
Informed consent was not applicable.Conflicts of interest
Masoud Shariati-Rad declares that he has no conflict of interest.References
- C. di Natale, A. Macagnano, F. Davide, A. D'Amico, A. Legin, Y. Vlasov, A. Rudnitskaya and B. Selezenev, Multicomponent analysis on polluted waters by means of an electronic tongue, Sens. Actuators, B, 1997, 44, 423–428 CrossRef.
- A. Rudnitskaya, A. Ehlert, A. Legin, Y. Vlasov and S. Buttgenbach, Multisensor system on the basis of an array of non-specific chemical sensors and artificial neural networks for determination of inorganic pollutants in a model groundwater, Talanta, 2001, 55, 425–431 CrossRef.
- K. Toko, Taste sensor, Sens. Actuators, B, 2000, 64, 205–215 CrossRef.
- S. Holmin, P. Spangeus, C. Krantz-Rulcker and F. Winquist, Compression of electronic tongue data based on voltammetry: a comparative study, Sens. Actuators, B, 2001, 76, 455–464 CrossRef.
- P. Ivarsson, S. Holmin, N. E. Hojer, C. Krantz-Rulcker and F. Winquist, Discrimination of tea by means of a voltammetric electronic tongue and different applied waveforms, Sens. Actuators, B, 2001, 76, 449–454 CrossRef.
- J. Riul, H. C. de Sousa, R. R. Malmegrim, J. dos Santos, A. C. P. L. Carvalho, F. J. Fonseca, J. Oliveira and L. H. C. Mattoso, Wine classification by taste sensors made from ultra-thin films and using neural networks, Sens. Actuators, B, 2004, 98, 77–82 CrossRef.
- T. Artursson, P. Spangeus and M. Holmberg, Variable reduction on electronic tongue data, Anal. Chim. Acta, 2002, 452, 255–264 CrossRef.
- L. Moreno, A. Merlos, N. Abramova, C. Jimenez and A. Bratov, Multi-sensor array used as an “electronic tongue” for mineral water analysis, Sens. Actuators, B, 2006, 116, 130–134 CrossRef.
- Y. Vlasov, L. Andrey and A. Rudnitskaya, Cross-sensitivity evaluation of chemical sensors for electronic tongue: determination of heavy metal ions, Sens. Actuators, B, 1997, 44, 532–537 CrossRef.
- Y. Mourzina, J. Schubert, W. Zander, A. Legin, Y. Vlasov, H. Lüth and M. J. Schöning, Development of multisensor system based on chalcogenide thin film chemical sensors for the simultaneous multicomponent analysis of metal ions in complex solutions, Electrochim. Acta, 2001, 47, 251–258 CrossRef.
- A. Riul, R. R. Malmegrim, F. J. Fonseca and L. H. C. Mattoso, An artificial taste sensor based on conducting polymers, Biosens. Bioelectron., 2003, 18, 1365–1369 CrossRef.
- A. Arrieta, M. L. Rodriguez-Mendez and J. A. de Saja, Langmuir– Blodgett film and carbon paste electrodes based on phthalocyanines as sensing units for taste, Sens. Actuators, B, 2003, 95, 357–365 CrossRef.
- A. Riul, A. M. Gallardo, S. V. Mello, S. Bone, D. M. Taylor and L. H. C. Mattoso, An electronic tongue using polypyrrole and polyanilin, Synth. Met., 2003, 132, 109–116 CrossRef.
- L. Sipos, Z. Kovacs, V. Sagi-Kiss, T. Csiki, Z. Kokai, A. Fekete and K. Heberger, Discrimination of mineral waters by electronic tongue, sensory evaluation and chemical analysis, Food Chem., 2012, 135, 2947–2953 CrossRef.
- W. Bourgeois, P. Hogben, A. Pike and R. M. Stuetz, Development of a sensor array based measurement system for continuous monitoring of water and wastewater, Sens. Actuators, B, 2003, 88, 312–319 CrossRef.
- R. Martinez-Máñez, J. Soto, E. Garcia-Breijo, L. Gil, J. Ibáñez and E. Llobet, An “electronic tongue” design for the qualitative analysis of natural waters, Sens. Actuators, B, 2005, 104, 302–307 CrossRef.
- S. A. Oyebog, A. A. Ako, G. E. Nkeng and E. C. Suh, Hydrogeochemical characteristics of some Cameroon bottled waters, investigated by multivariate statistical analyses, J. Geochem. Explor., 2012, 112, 118–130 CrossRef.
- T. Li, G. Sun, C. Yang, K. Liang, S. Ma and L. Huang, Using self-organizing map for coastal water quality classification: Towards a better understanding of patterns and processes, Sci. Total Environ., 2018, 628–629, 1446–1459 CrossRef.
- H. Yan, Z. Zou and H. Wang, Adaptive neuro fuzzy inference system for classification of water quality status, J. Environ. Sci., 2010, 22, 1891–1896 CrossRef.
- J. Hammes, J. A. Gallego-Urrea and M. Hassellov, Geographically distributed classification of surface water chemical parameters influencing fate and behavior of nanoparticles and colloid facilitated contaminant transport, Water Res., 2013, 47, 5350–5361 CrossRef.
- M. Filella, I. Pomian-Srzednicki and P. M. Nirel, Development of a powerful approach for classification of surface waters by geochemical signature, Water Res., 2014, 50, 221–228 CrossRef.
- P. R. Kannel, S. Lee, S. R. Kanel and S. P. Khan, Chemometric application in classification and assessment of monitoring locations of an urban river system, Anal. Chim. Acta, 2007, 582, 390–399 CrossRef.
- T. Kowalkowski, R. Zbytniewski, J. Szpejna and B. Buszewski, Application of chemometrics in river water classification, Water Res., 2006, 40, 744–752 CrossRef.
- G. J. Hall and J. E. Kenny, Estuarine water classification using EEM spectroscopy and PARAFAC–SIMCA, Anal. Chim. Acta, 2007, 581, 118–124 CrossRef.
- J. Lia, H. Huang, X. Sun, D. Song, J. Zhao, D. Hou and Y. Li, Development of fluorescence sensor array for the discrimination of metal ions and brands of packaged water based on gallate modified polymer dots, Anal. Methods, 2019, 11, 3168–3174 RSC.
- Y. He, Y. Liang and H. Yu, Simple and Sensitive Discrimination of Amino Acids with Functionalized Silver Nanoparticles, ACS Comb. Sci., 2015, 17, 409–412 CrossRef CAS.
- I. Sanskriti and K. K. Upadhyay, Cysteine, homocysteine and glutathione guided hierarchical self-assemblies of spherical silver nanoparticles paving the way for their naked eye discrimination in human serum, New J. Chem., 2017, 41, 4316–4321 RSC.
- R. G. Brereton, Chemometrics Data Analysis for the Laboratory and Chemical Plant, John Wiley & Sons Ltd, The Atrium, Southern Gate, Chichester, West Sussex, England, 2003 Search PubMed.
- D. Ballabio, A MATLAB toolbox for Principal Component Analysis and unsupervised exploration of data structure, Chemom. Intell. Lab. Syst., 2015, 149, 1–9 CrossRef CAS.
- B. Chen, F. Li, S. Li, W. Weng, H. Guo, T. Guo, X. Zhang, Y. Chen, T. Huang, X. Hong, S. You, Y. Lin, K. Zeng and S. Chen, Large scale synthesis of photoluminescent carbon nanodots and their application for bioimaging, Nanoscale, 2013, 5, 1967–1971 RSC.
- T. Liu, J. X. Dong, S. G. Liu, N. Li, S. M. Lin, Y. Z. Fan, J. L. Lei, H. Q. Luo and N. B. Li, Carbon quantum dots prepared with polyethyleneimine as both reducing agent and stabilizer for synthesis of Ag/CQDs composite for Hg2+ ions detection, J. Hazard. Mater., 2017, 322, 430–436 CrossRef CAS.
- J.-C. Jin, Z.-Q. Xu, P. Dong, L. Lai, J.-Y. Lan, F.-L. Jiang and Y. Liu, One-step synthesis of silver nanoparticles using carbon dots as reducing and stabilizing agents and their antibacterial mechanisms, Carbon, 2015, 94, 129–141 CrossRef CAS.
- N. V. Mehta, S. Jha, H. Basu, R. K. Singhal and S. K. Kailasa, One-step hydrothermal approach to fabricate carbon dots from apple juice for imaging of mycobacterium and fungal cells, Sens. Actuators, B, 2015, 213, 434–443 CrossRef.
- P. Gemperline, Practical guide to chemometrics, CRC Press Taylor & Francis Group, 2nd edn, 2006 Search PubMed.
- R. G. Brereton, Applied chemometrics for scientists, John Wiley & Sons Ltd, Chichester, England, 2007 Search PubMed.
- L. Kaufman and P. J. Roussew, Finding Groups in Data - An Introduction to Cluster Analysis, A Wiley-Science Publication John Wiley & Sons, 1990 Search PubMed.
- M. Shariati-Rad and Z. Ghorbani, Carbon dot based colorimetric sensor array for discrimination of different waters, Anal. Methods, 2019, 11, 5584–5590 RSC.
Footnote |
| † Electronic supplementary information (ESI) available. See DOI: 10.1039/d0ra06000c |
| This journal is © The Royal Society of Chemistry 2020 |